Intro
Hypercard in the World was a live programming environment for the real world.
It was a kind of operating system for programs running on real-world objects.

In this system, you could point with a laser pointer to the four corners of any physical thing, to “bless” it as a programmable object.

You could now write code that runs on that object, and interacts with all the other objects in the space.

With Hypercard in the World, we could start asking questions like, what is it like to read a book while seeing the entire book at once?

Or what is it like to watch a video with an interactive poster that shows the entire video at once and lets you navigate freely around it?

What is it like to browse all of the past projects from everyone in the group in the form of an interactive searchable poster gallery?

What is it like to make interactive dioramas together with other people, or to paint on the wall?

Hypercard in the World was, to a certain extent, implemented in itself, as a large interactive poster in which you see data flow in real time and can live modify both the code and the data on the poster itself.

In this video, I'll give some of the backstory leading up to the creation of Hypercard in the World, and I'll go into some detail about the various projects that were made in it, including some of the games that were made at our three-day game jam.
I'll show how the system works via Bigboard, which is the implementation of the system in itself.
This work was done in early 2015, and most of the demonstrations you'll see here were recorded in 2016. I'm editing this video right now from 2024, so I'll conclude with a bit about what happened after this project.
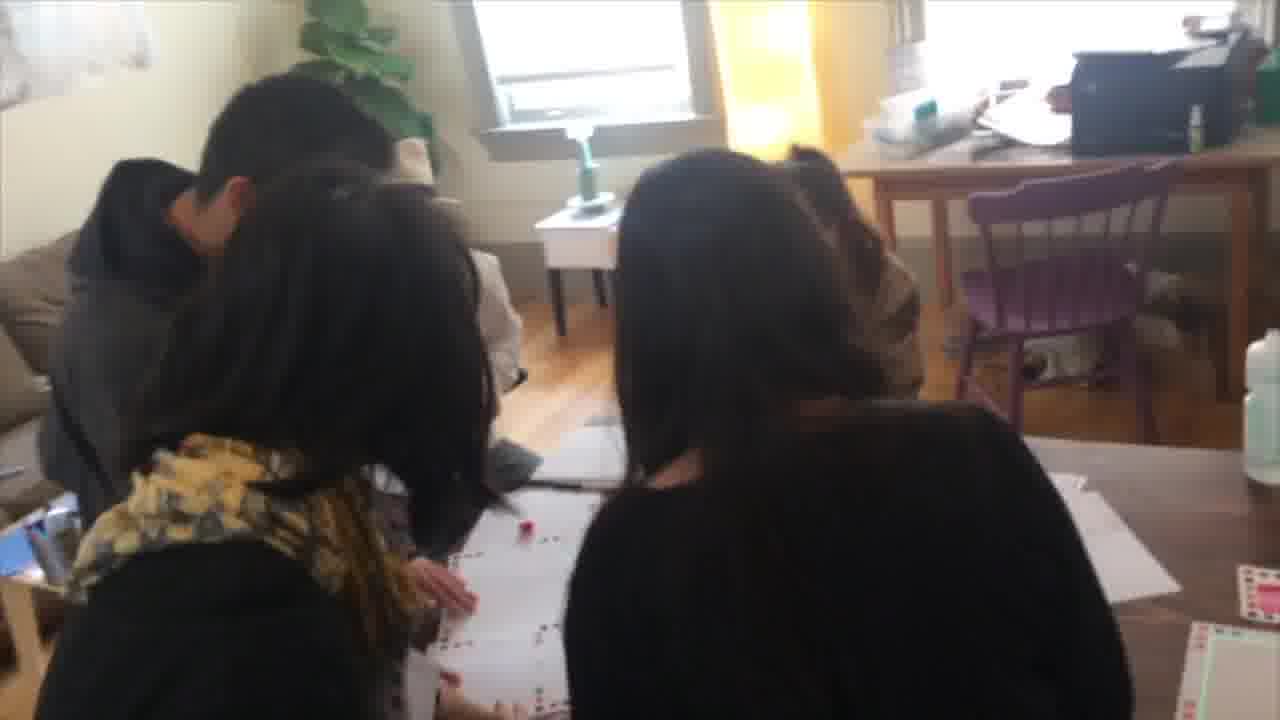
It led to a subsequent system called Realtalk, which led to a place called Dynamicland, and those projects are still very much active.
Escaping the tiny rectangle
The Communications Design Group was started in 2014, a research lab chartered with inventing new computing systems to support fundamentally new ways of thinking and communicating. [more]

In the lab's first year, we published a number of screen-based works, in which the reader was surrounded by rich context or directly manipulated explorable models. [1] [2]

But our primary interest was not computers. It was how ideas could be represented and communicated.
In order to get real context and direct manipulation, we also found ourselves designing many things that were not in computer screens, and couldn't be. [more]

Here's a passage from a Bruno Latour essay, redesigned as a six-foot poster comic whose structure is visible from a distance away. [more]

Here's the table of contents of Neil Gershenfeld's book on mathematical modeling, as a kind of toolbox poster that you can browse when you need a mathematical technique. [more]

These are a couple examples of spatially represented text. There was also a lot of interest in spatially representing video.

This huge poster shows every frame of the film Hemingway and Gellhorn. That led to many subsequent posters showing every frame of a video, exploring various designs and organizations. [more]

Here's a talk that I had given redesigned as a poster comic, whose structure is browsable and readable at different scales. [more]
This is an earlier talk as an interactive poster.

It has eight iPads embedded in it, one for each chapter. You can scrub through the video by sliding your finger along a touch-sensitive strip of thumbnails below. [more]

Here's a binder where every page represents a video, and you can navigate through the archive by turning the pages. [more]

And another book where, as you turn the pages, key passages highlight and related video plays. [more]

Here's a representation of all the pages of a book chapter, which you browse by moving your body left and right. [more]

Here's a book that generates physical receipts as you browse Wikipedia in conversation. [more]
These receipts were taped up on the wall, providing a spatial record of past conversation. [more]

Going beyond flat paper, this is a diorama timeline, a three-dimensional timeline of the key events in a particular book, to be glanced at while reading in order to maintain context. [more]

And a similar idea, suspending the timeline above the reading area in a hanging mobile. [more]

These sculptures are three-dimensional plots of mathematical functions. [more]

This is a stretchy sculpture of a brain scan. [more]
So, within the group, there was a lot of interest in how ideas could be represented and communicated outside the tiny rectangle of the computer screen.
The origin of Hypercard in the World was, in fact, a poster gallery.
We wanted to make a gallery of our past work, where each project would be a label on a poster.

It was Glen who expressed the wish that the label could somehow link back to the project documentation.
We had the idea of pointing at the label with a laser pointer.
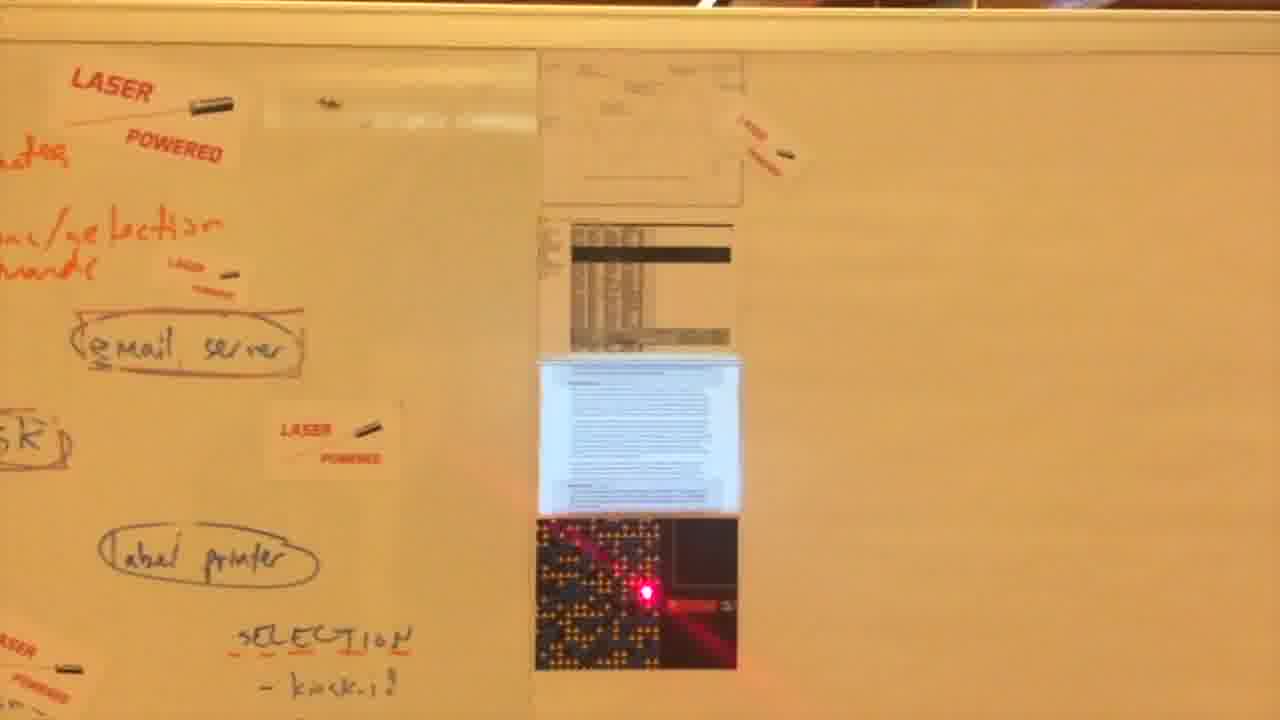
That evening, Robert already had a prototype working, and from there we were off.
The first iteration of a complete programming environment came together in a couple weeks. [more]

What I want to emphasize here is that Hypercard in the World, and subsequent systems, started with media, and then added computation.

Many other projects take computers as their starting point, and then try to force-fit computers as they are into some sphere of human activity. They try to make media out of computers.
This project started with posters and dioramas and spaces. It started with forms of spatial media that already work really well, and fit well into a human environment.

Hypercard in the World lightly augments these physical media with computation, to help them better express context and dynamic behavior, but their essence is still posters and dioramas and spaces.
Dynamic library
I feel like one of the most important parts of understanding is seeing context.

If you want to understand a thing, it's not enough to just see that thing in isolation. You really want to see the entire space of things, and where that thing fits in in the big picture.
One of the nice things about getting outside the tiny rectangle is that there's all this room to show that kind of context.
One simple example of that is if you're reading a book.

When you're reading a book you can only see the page that you're on. That sounds really obvious, but this book is a hundred pages.
The book is this very large, detailed structure, and when you're reading you're looking through a pinhole.

You can only see a little bit of it at once. You have to keep the larger structure in your head.

When you're reading on a screen, it's even worse. Here, you have much less sense of where you are in the structure. You're much less physically grounded.
So, on a screen, it's much more of just one thing after another after another.
We thought it might be interesting if you could be sitting on the couch, flipping through a book, and you can always glance up there, say above the shelf, and see a map of the entire book. [more]

The big blocks you're seeing up there are the chapters in the book, and you're seeing every page in every chapter.
There's one page that's popped out. You'll notice that as I flip through the book, that marked page is going along with me.
At any moment, I can just glance up, and I see exactly where I am within the chapter, and exactly where that chapter is within the entire work.
When you're reading, in your periphery, you're always seeing what came before, what came after. That's one of the things that a map gives you. It lets you stay grounded.

Another thing that a map gives you is it lets you move around really freely.
So, say, I'm on this page and I see this figure, and this reminds me of a figure that was over in the previous chapter.
I can see it, it's the green one. I want to take a peek at that.
I can take this laser pointer — it's just an ordinary laser pointer — and point over to that figure, point over to that page, and now I'm on that page.

I can go back to where I was. Or, I could say, what he's talking about here, I like how he summed that up near the end of the book.
But his summary here, maybe that contradicts what he was saying over here in this chapter. Let me jump over to that.
You can move freely around the work as you make associations in your head. The connections that you make knit together this larger work. You're not trapped in this linear tunnel vision.

What you're seeing here is a page within the chapter, and a chapter within the book.
But there's this other space of information here, which is the book within the shelf. This is also a kind of map of knowledge. Maybe we want to do the same thing here.

I can point to a book on the shelf, and it lights up, and we see the map of that.

This is Computer Lib / Dream Machines, which doesn't really have chapters.
But next to it is an early Whole Earth Catalog, because I wanted to see what those pictures would look like.

Next to that is a monster 450-page Whole Earth Catalog, because I wanted to see what this design would look like with so many pages.

What we're doing here is not just pointing to virtual objects rendered on a screen, but we're also pointing to real physical objects, meaningful physical objects in the real world. That's going to become really important.
This is one way of drawing the map of a book. And we went through a number of different designs for that.
One we started with was this one, where you take all the pages of the book and blend them together in this kind of smoosh.

That was interesting, but I thought, maybe we'll take this page, and shrink it down a little bit, and lay them out on a grid.

And I thought, okay, that needs more structure. We want to be able to see the chapters. In the next design, the chapters are these long strips of thumbnails. And they highlight, so you can always see what chapter you're in, and where you are in that chapter.

Then I started getting into columns. Instead of running the thumbnails all the way across, maybe each chapter has its own little column, and the thumbnails wrap around in there.
I'm showing you these different designs by pointing over here on the whiteboard. These are literally just boxes I drew on the whiteboard with whiteboard marker.
I even annotated them. This was March 2, this was March 9. I just scribbled that on there.

The code that's drawing these maps up here is inside this box, at least conceptually. This is kind of a hint that what we're showing here is not some specialized installation for drawing pages above a shelf.
I'm actually standing in a kind of room-sized authoring system for creating dynamic spatial media. There's a kind of operating system which is running the entire space, which we've nicknamed Hypercard in the World.

The way it works is: you start with real physical objects such as a box on a whiteboard, or a book, or a wall. You point at the four corners of that object and you “bless” it. Once the object's blessed, now you can write code that runs on it.
The object can see the other objects and communicate with them and draw on them and whatnot. I'll talk a lot more about authoring at the end.
But I wanted to give you a little preview of how this works, because I'm going to be showing other projects made in this system, and I want you to see that it's not really magic.

This object right here, I can inspect it by pointing to it and hitting the “inspect” button.
You can see that that object has a few things. It has an identity, which gives it a name. It has a location, which says where it is.
And it has a little bit of code, which is what's drawing that map above the shelf.
And I could change that code. Or I could do something more interesting, which is to say, I want to make a variation on that.

I'm going to draw my own little box on the whiteboard. And then I'm going to duplicate the object I'm inspecting onto this new object that I just drew.
I was a little sloppy with the blessing there, so I'm going to tighten up the corners a little bit in the inspector. That's good enough.

Now we have this object and this new object, right now, both drawing the same thing. But maybe I want to change this.
The selected page is, right now, being drawn popped out. I might say, actually, I want to draw that a little bit differently. Maybe I want the selected object to be drawn with a red border.
I can make the changes to the code to do that, and I'll hit “save”.

Now you see the selected page is being drawn with a red border. And on the old one, it's being drawn popped out. So now, this guy's drawing it differently.
There's nothing magic about this particular whiteboard. I could, for example, take a sticky note and put it... I could put it anywhere in the room. Then I can duplicate the object that I just made onto this sticky note.

Now it's the sticky note that's drawing that map up there. I can switch to that view, or I could select this object and now it's drawing it.
There's more to this than sticky notes and whiteboards, and like I sais, we'll get to that in a bit.
I'm showing this because I want to emphasize that what we're working towards here is not some app that people download that draws stuff in their environment.

What we're working towards is a medium that enables people to create these sorts of things for themselves, for their own needs, in a way that makes sense for their own environment, for their own context.
In the same way that if I give you a piece of paper and a pen, you can draw or write anything that you know how to, we want to work towards a medium where people can create dynamic spatial media for what they want to do, in their own environment.
And then that medium has to be paired with education and a corpus of really great examples, so people have good ideas of what to make.
Dynamic poster
This is a talk that I gave a couple of years ago. [more]
You can go to Vimeo and hit “play”, and stuff will happen at you for twenty minutes or so. And then you'll walk away thinking, okay, that was entertaining, but what did I just see?
A video is a very ephemeral thing. You can't see any larger structure. It's just one thing after another after another. There's nothing really to hold onto.
So I redesigned this talk in the form of this poster comic strip. [more]

The text here is the talk verbatim, so you can just start at the top and read your way all the way to the bottom.

You can also see the larger structure. From twenty feet away, you can still see, there's the purple section, the blue, and the green.
And as you get closer, you see the subsections, you start to see the pictures. And when you get all the way up to it, you can start reading in depth.
So it allows for a variable level of detail, which lets you skim, you can browse, you can get a gist at a glance. All these things that are normally really hard to do in time-based media.

The poster is also a physical object in the world. It's persistent. We walk past it every day.
That means that these ideas that are embodied here, they have a physical home, they have a location.

We can be anywhere in the lab, and if we start talking about these things, we have somewhere to point to, or we can walk over here.
It has a very different feeling than ideas that you've only seen pop up on a computer screen, then go away.

So this is a nice map of a video. But it's not video.
In video, you can hear somebody talking, you can see the animation. We don't want to lose all those things. [more]
So what you can do is, you can take this laser pointer...
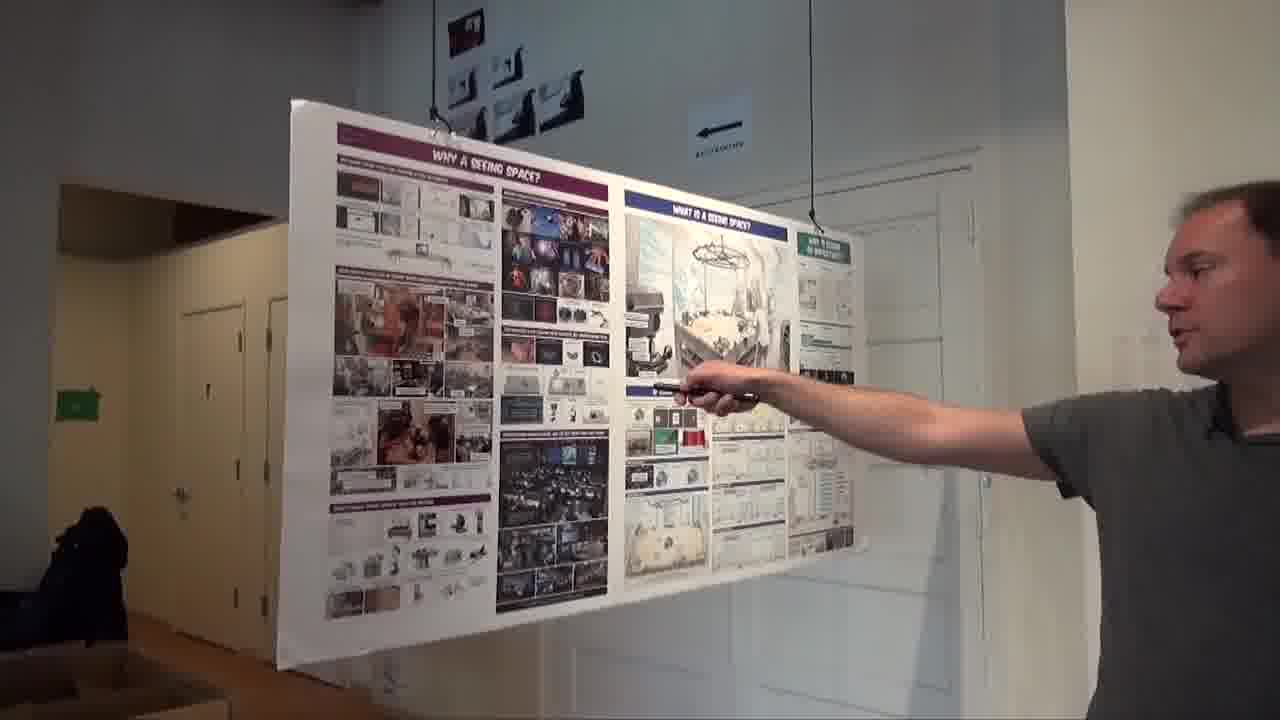
and point to a panel. It highlights, and you see the video starts playing on the far wall.

And as the video plays, you see the highlight is moving from panel to panel. So this is your playhead.
But unlike a normal playhead, it's in a structured space where you can see you're in this section, you can see what came before, you can see what came after.
So like the map of the book, it lets you stay grounded. You always know where you are.
And also like the map of the book, it lets you move around.

If what you're hearing here makes you think of something that was back here, okay, now you're back here.
Or you can jump ahead. You have the freedom to move around the work, as you make associations in your head, and as you make connections. You're not trapped in the author's linear narrative.

Something interesting came up here from a UI perspective when we were making this.
When you're reading the poster, you're normally pretty up close to it, because the text is kind of small.

And then if you start playing the video from some point, the video starts playing, but it's mostly occluded by the top of the poster. So you involuntarily take a few steps back.
And then, without even thinking about it, you've now positioned yourself in a place where you can see both the entire video and the entire map in your field of view. They're in the periphery of each other.

You switch between looking at the video and the map by refocusing your eyes to a different plane.
If you've ever struggled with UI designs where you're trying to cram a whole bunch of context on a computer screen, and you've got detail views and overviews and affordances for switching between the two of them...
All of that fighting over screen real estate just becomes irrelevant, when you can use surfaces in the real world. Readers can look between them, switch between them by just looking at different ones, or moving their body around.
I want to show a quick peek of how this is implemented, just to show that there's not really any magic happening here.

So, the poster is a blessed object. I just pointed to the four corners and added a little bit of code to it.
And the individual panels are also objects. There's really not much to them. Basically, I just gave them a name, which was their timestamp.
And then the poster has a little bit of code that says, when one of my children is selected, tell the video player object on the far wall to start playing from that timestamp.

You'll notice that the big panel right here isn't doing anything yet, because I haven't bothered to hook that up. So I'm going to do that now.
I'm just going to point to the four corners, like so.
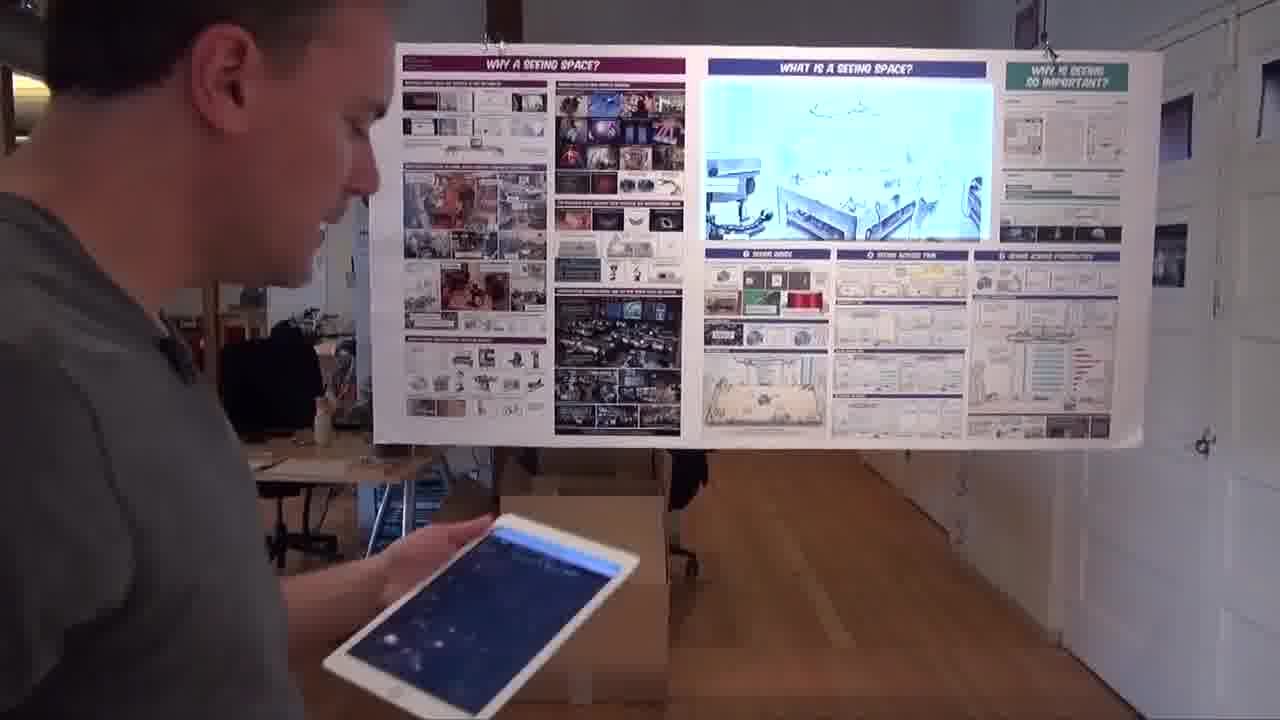
And I need to give it a name, which will be the timestamp that we want to start playing the video, which is, I think, 6:04.
And now when I select that panel, the video starts playing from that point. It's just another panel.
Research gallery

This is our research gallery. This is the meta project which lets us get to all of our other projects. [more]

These posters here are just pieces of foamcore that are hanging from the ceiling. And these are printed-out sticky labels that represent the different projects that we've done over the years.
Where this came from was, as a research group, we develop our ideas by making lots of little prototypes.
So, you might make your project and send it out on the email list. And someone else might see it and riff on it. And there'll be this flurry of activity around an idea for a little bit.
And then a few months later, it's just totally forgotten. It's buried in the bowels of your email. You never see it again.
Email is this very ephemeral thing that just flashes by on a screen and goes away.

So we were trying to think of a way where we could surface this work that we've worked on, and give it a more persistent physical form, where we can see it and walk past it every day.
Now what we do is, we send out our email just like normal, but then come over here and laser this spot on the ground that says, “design a label”.
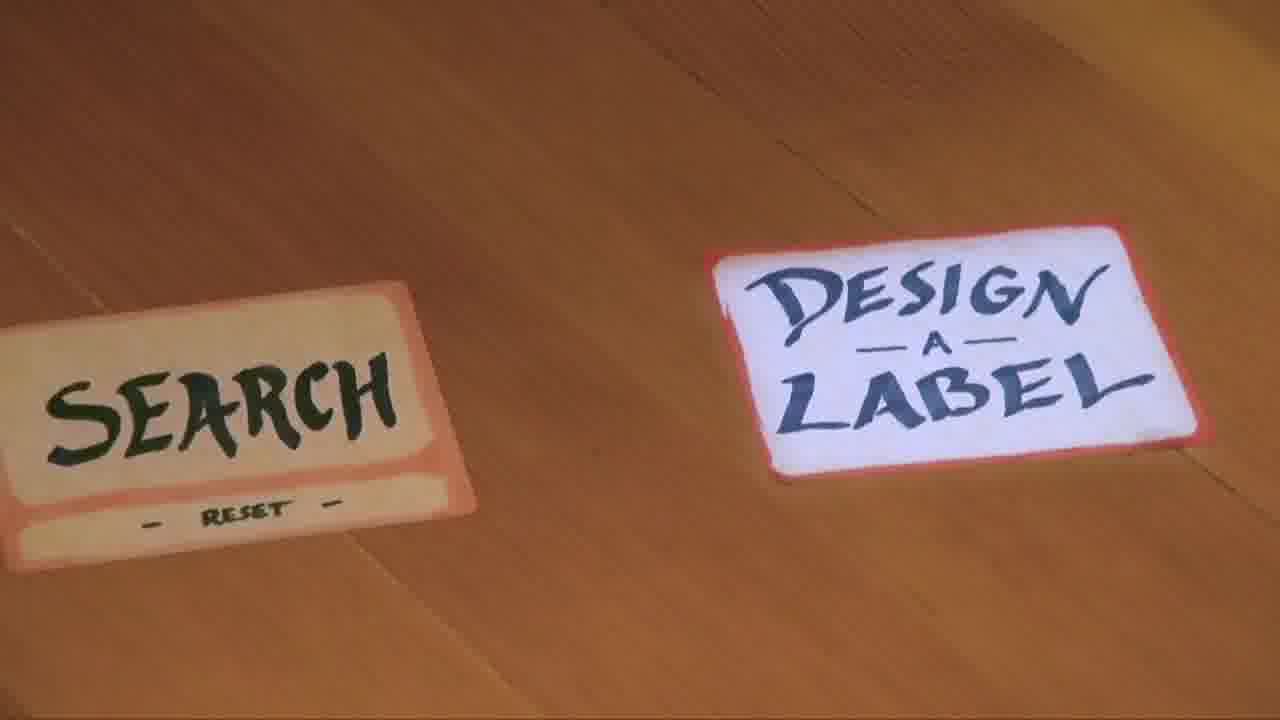
The email list comes up over here, and you'll just click on your email, and it designs a label. You hit this button that says “print label”.

A sticky label comes out of the printer here. You just take this label and stick it on the next open spot on the poster board.

Then, the last step is to bless that label that you just put there.
In the inspector, you point to the four corners. You can be a little sloppy, because the poster will snap it to the grid. And I add a design attachment, which basically just tells it which label it is.
Now, when I point to that label, the project comes up over here on the screen.

I can point to any of these things. And they come up over here.

So, this is a kind of map of the work that we've been doing over the last couple of years. Visitors can come in, and we can come over, and we can see everything that we've done, in context.
It doesn't matter whether the project is from two years ago, like Glen's project here, or if it was something just from last week. Everything is just one point away. We can make these connections across time.
What you're seeing on the screen here, when I select one of these things:
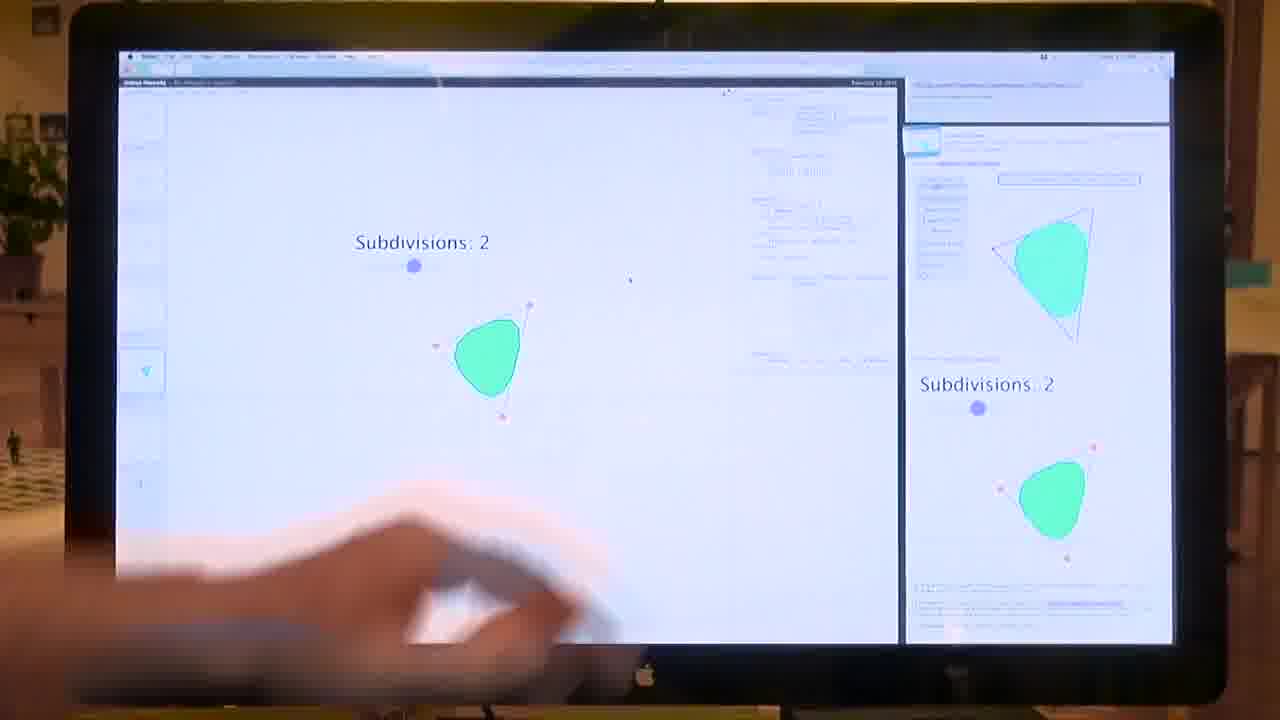
Over here on the left is the prototype or the video or whatever it is the project's about. And over here on the right side is the email thread that it was on.
So you don't just see the thing. You see the entire discussion around the thing.
It doesn't matter how long ago this thing was. You're brought back into the conversational context that it came out of. You're not looking at things in isolation.
Speaking of context, you'll notice that when I select some of these, some of its neighbors highlight in yellow.

That's because they're on the same email thread.
So, the map is stable. These labels don't shift around. We show related things by highlighting relevant subsets within the staple map.
For example, over here, when I select this guy, you'll see, okay, there are three more contributions to that thread, and then something else a few months later. That just pops out at you.

We use the same technique of highlighting in context to show search results.
Over here on the ground, there's a spot marked “search”. I point to that, and I can say, what has Toby posted?

And so we see that.
Or what has Glen been up to? It searches for Glen.
Or, Toby and Josh have been working on a project called Apparatus, and now you can find the Apparatus-related thing that you were looking for.

This way of showing search results is very different than, say, the Google style — a list of ten things that are just totally decontextualized, where you can't see any relationship to other things or to any larger space.
What we're trying to do with this project, and with a lot of these other projects, is to create a stable, persistent map of the space, and to always be seeing things in that context.
Serengeti

This is the Serengeti, a HyperCard-like dynamic diorama. As you laser each animal, it makes its sound. [more]

This diorama was put together over time in a shared physical space.
Because it was out in the open, instead of in a computer screen, it naturally attracted collaborators who worked together side-by-side.

Eventually everyone in the group put at least one object into the scene, some simple and some with advanced behavior.
Here I'm going to add a new animal to the scene.
I bless it by pointing to its four corners.

And now I record a sound for it with my voice.
I save the sound file, and give the object the name of the sound file I just recorded.

The label on the wall to the right is the Wall Audio Player. That's the object that's watching the animals on the table, and playing their sounds when they're selected.

You can put your face on the bunny.
A program for recording a stop motion animation is attached to the bunny itself. I bring up the bunny in the inspector, run its program, and record a new animation.
Now, I'm going to add a chameleon to the scene.
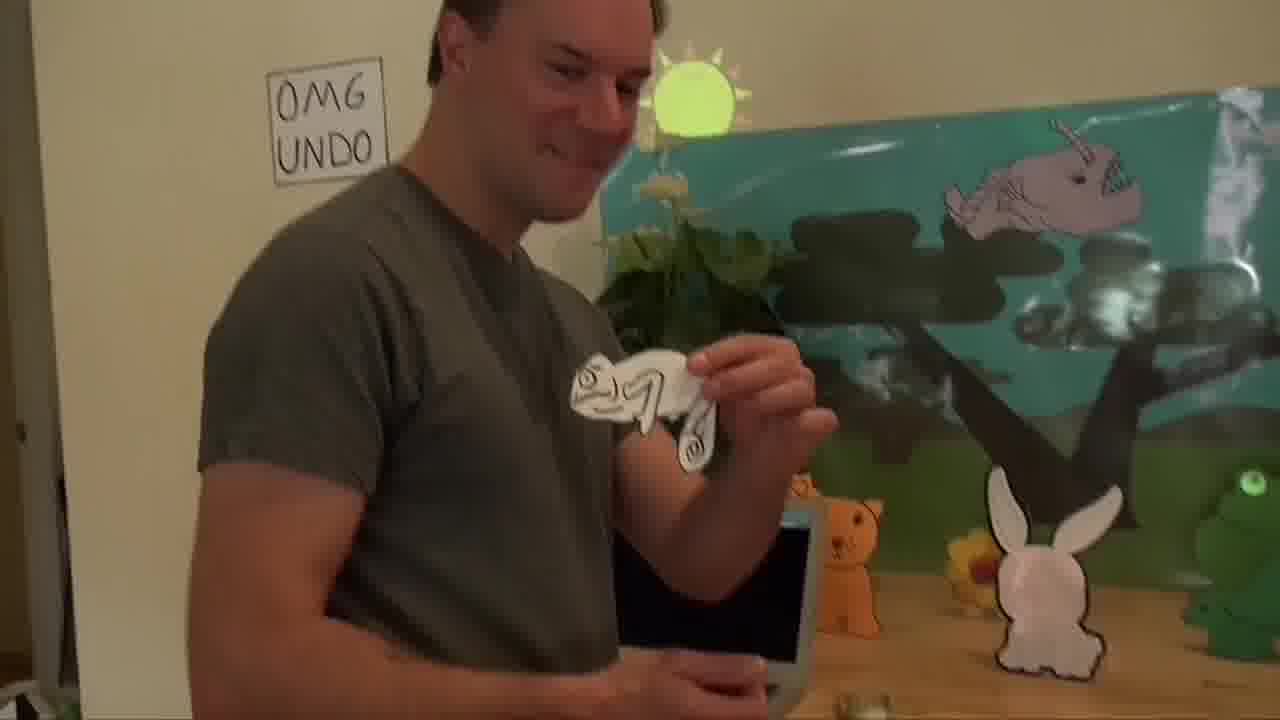
The chameleon is going to live on the leaf of a plant.

After blessing the chameleon, I attach a four-line program to it which will make it change color when a color swatch on the wall is selected.
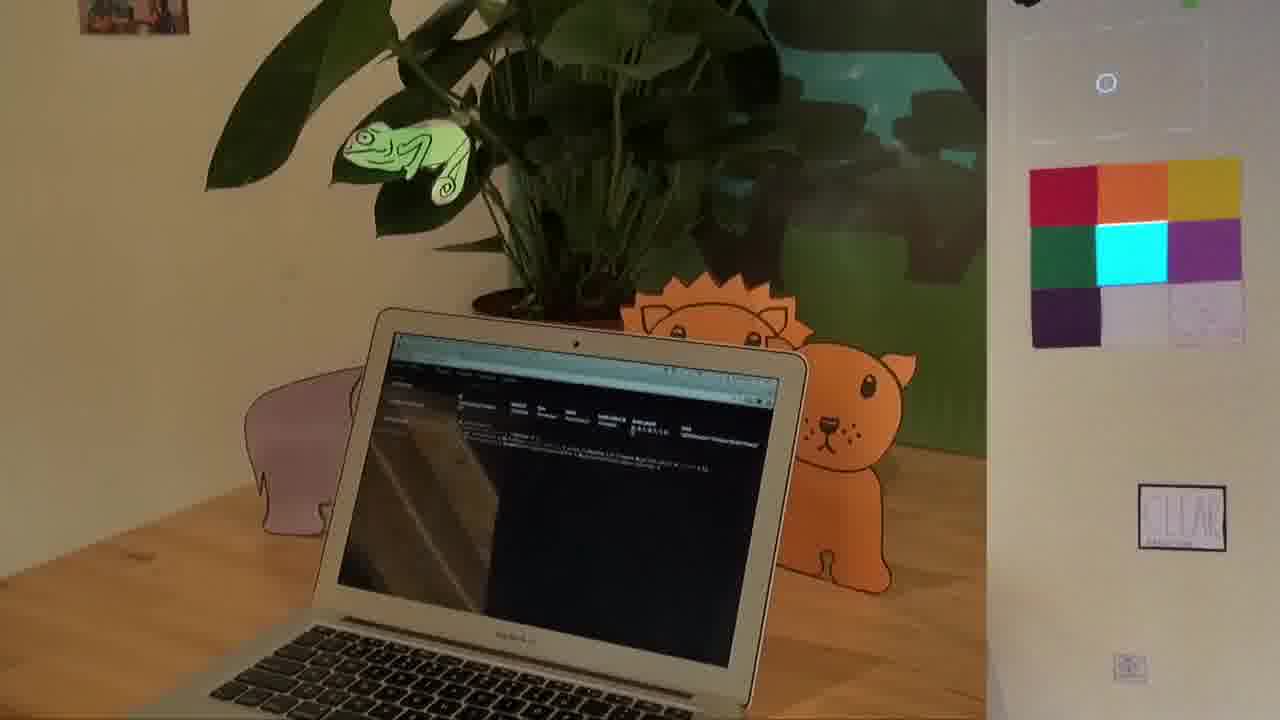
Here, I'm pointing at different colors in the color palette, and the chameleon is changing color.

Here, I'm using that same color palette to paint a picture on the wall above the Serengeti. [more]

The painting program is attached to the wall itself, and I could edit it by bringing the wall up in the inspector.
Movie-watching

The research group would occasionally watch movies together, and we'd sometimes experiment with ways of augmenting the viewing experience or the discussion afterwards. [more]
Sometimes those experiments would use Hypercard in the World.

When watching this film, everybody had a laser pointer. When you laser at the screen, a vote counter would go up. If enough people voted, we'd pause the movie and have a short discussion at that point. [more]

We also found that it's just fun to watch a movie with laser pointers.

For watching this talk, we hung up printouts of the slides to the left of the screen. [more]
The black moving bar you see is the playhead. It shows what slide we're on, and our progress through it.

At any time, a viewer could laser the screen and it would leave a bookmark at the current position, in the form of a red bar, to remind the viewer of a point that they wanted to bring up during the discussion afterwards.
The act of bookmarking was visible to everybody.

We watched this video with a shared-annotation prototype, and later made this poster transcript with our annotations on it. [more]

You can laser a thumbnail on the poster to start playing the video from that point on an iPad.

I found that the group's annotations would act as landmarks in the map.

I would use the poster by spotting someone's comment, lasering it to play the video from there, and then listening to the video while scanning the poster for a connected or related idea, usually in someone else's comment.
I'd then jump the video to there and scan for the next connection.
Game jam
We held a game jam in Hypercard in the World, in which members and friends of the research group spent three days making laser-powered games in physical space. [more]

Many of the participants had never previously made anything in the system.

We started with a short tutorial, including sample code running on the wall.
By the end of the three days, ten games were made and presented.

Mole Tank is a room-scale competitive whack-a-mole for four players. Each player chooses a color, and runs around the room lasering moles of their color. [more]

In Laser Socks, you attempt to laser your opponent's socks, while dancing to avoid them lasering your socks. As your socks are lasered, your life bar fills up. [more]

In Standoff, you wait for the music to change, then spin around and attempt to shoot your opponents. [more]

Tamagotchi Island is a long-running game where over the course of the day, you catch fish to feed the inhabitants of the island.

In Laser Trains, you build a physical train track in such a way that the laser pointer taped to the train lasers a sequence of stars on the wall.

Pong is a room-scale Pong game where, when the ball goes off one wall, it emerges on another wall elsewhere in the space.

In the game We'll Get Through This Together, players have to collectively bounce a laser off of handheld mirrors to restore health to sick flowers.

In contrast to a normal screen-based game jam, every game that was made here was multiplayer. This wasn't agreed upon in advance, it was just a consequence of designing for the real world.

Games intended for two players worked even better with four, six, or more people joining in.
And unlike what we typically think of as “social games”, most of the games here centered around body movement and physically interacting with other players.
Also, most games generated very rich experiences with very simple code.
Bigboard

This is Bigboard, and Bigboard is the implementation of the Hypercard in the World system. [more]
Hypercard in the World is our authoring environment for creating dynamic spatial media, such as those large active posters made out of physical things. And here it is implemented in itself, as a large active poster made out of physical things.

Each one of these things is an object in the system, and over here in the inspector, I can point to any one of them and bring it up.
These blue pieces of paper have code attached to them. If you got close, you could actually read the code that's printed on it. And these large pieces of foamcore have data collections.
The way the system works is...

up here, this bit of code is looking in the cameras and looking for bright dots.
We have cameras in the ceiling, and the exposure is all the way down, so they see black most of the time, unless there's something super-bright like a laser.

You can see this camera is seeing a point at that x-y position.
This bit of code is dumping the results into this data collection.
If there are two bright dots, then it sees both of them.
If the dot's over there, then it sees it in a different camera.

Then, this code is mapping this collection into that collection.
Here, we have dots in a camera, and here it's creating a unique tracking document for each one, so we can track each of these dots individually, in case multiple people are working together on the same board.

And then this code is looking at that, and doing a hit test.
This is a point in camera space, and this is saying, is there any object at that point? And if so, we translate it into a point on that particular object.
So we can see here that I'm pointing at the Bigboard. And if I go over here...

I'm pointing at the “strip above bookshelf”, and that's what it says.
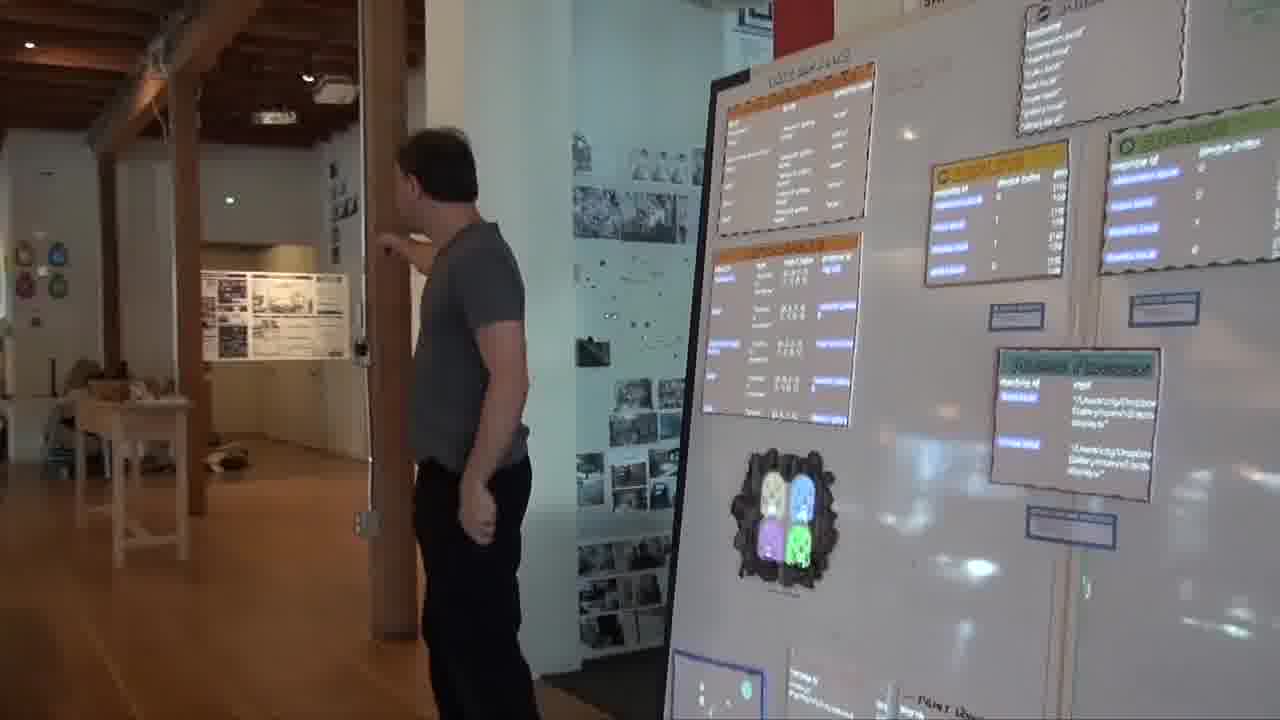
I can point at the “wall above bathrooms”, or I can point at the Seeing Spaces poster.
These are root objects, meaning that they're defined by where they are in the camera space.

Objects can contain objects inside them, so this is doing a hit test within that object to find contained objects.
So you can see here, I'm pointing at the “lasered objects” object. And there it is, “lasered objects” at depth zero. And its container, Bigboard, is behind it at depth one.
Anything I point to here is going to show up in this collection. I'm just pointing around the room right now.

You and I can look at this collection and see what the system thinks is being lasered. The code that's running does exactly the same thing. The code watches the same collection, sees the same data.
So when you're writing the code, you don't have to imagine this data in your head. You can just see the data that's flowing through the system and write the code to respond to exactly what you're seeing. I'm going to get back to that in a bit.

Many things are watching this collection. One of them is over here, the selection machinery.

We have this way of selecting objects.
This is just a crosshairs thing that I use to see how far off the calibration is.

But here I've selected it, and this is a collection of selected objects in the room.
The crosshairs is selected. One of the books in the library is selected. One of the labels in the research gallery is selected.
And then the way that processes work is, you can attach code to objects. When that object is selected, that code runs.
That's what these things are doing. They're watching this collection.

And then when an object is selected, if there's code attached, it turns into a process.
These are daemon processes which run in the background. And these are illumination processes which can draw on objects.
You see this crosshairs has an illumination that's running. Its target is the Bigboard. So now it can draw on the Bigboard. And that's exactly what it's doing.
If I deselect it, now that process goes away.

What this is, is a kind of map.
In the same way you saw a map of a book, or a map of video, or a map of research work and emails, this is a map of a software system. And it also is functioning as the working implementation of that software system.
I think there's a couple of interesting things here.
One that we've noticed is that someone can come in and just stand here, play around with this, watch the data flowing through the system, maybe inspect a few things.
And they'll be like, okay, I get it. I understand how this works.
Some people might even say that it's obvious and trivial. Why did you have to make this big board for a system that's so obvious and trivial and simple?
And I know that it's not obvious and trivial, because the previous version of this was not a big board. The previous version was code in text files.
I even had a lovely full-screen database viewer... [more]
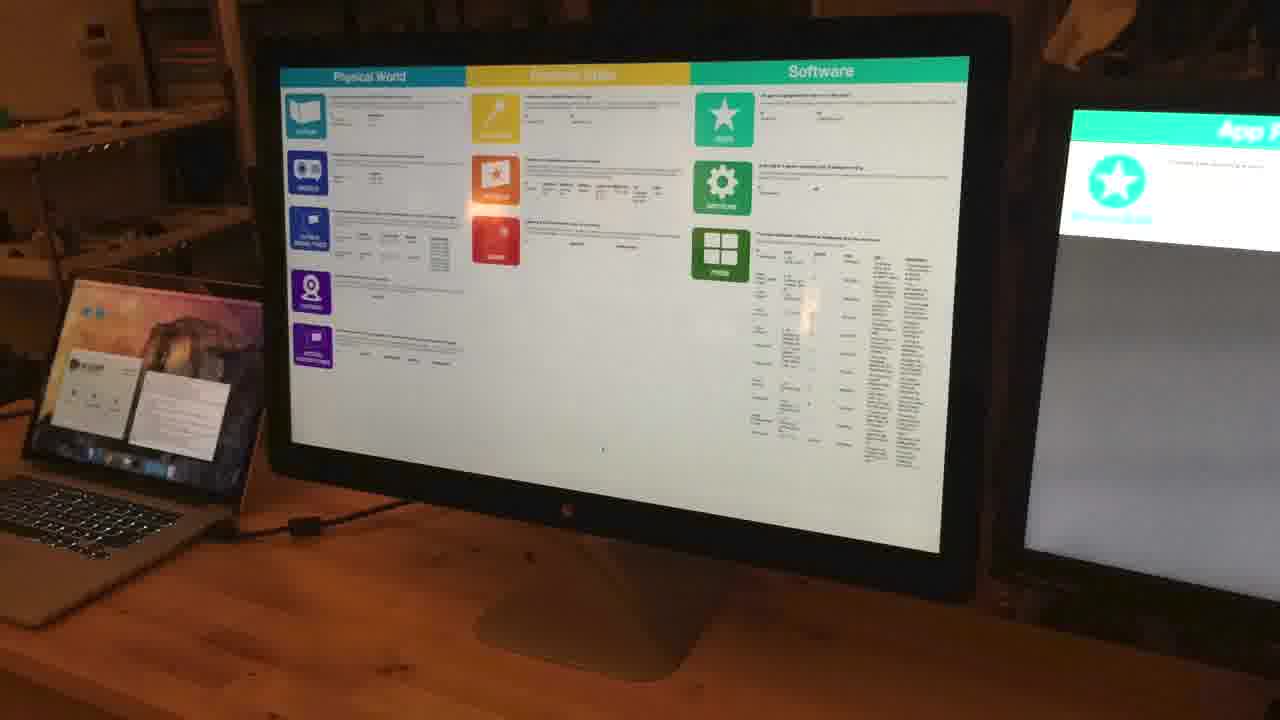
where you could see all the data, and you could read captions that described what the data did.
Nobody understood how it worked.

With this thing, everyone around here understands how this works, even if they don't care.
Because you walk past it every day. You overhear people talking about it with other people. It's part of the environment. You kind of can't not understand it.
That's what happens when you give a system the room that it needs to really represent itself and express itself. It goes from seeming opaque to seeming trivial and obvious.

The second interesting thing about this is the degree to which everything is spatialized.
In the system, every bit of code and every bit of data has to live on a physical object. It has to have a place where you can get to it and see it.
So if I want to change how selection works, for example, you come here.

You inspect this object, because that's where the code for selection is.
It's not floating in some GitHub repository, it's not in some icon that scrolls through your screen and disappears.
Conceptually, the code is attached to these atoms right here.
If you want to add a camera to the system, it goes in here.

If you want to add a projector to the system, it goes in here.
So this is a very different way of thinking about a software system.
It forms a very concrete map, where you know where everything is. And that map is shared with the other people that you're working with. Everybody kind of agrees on where everything is.
There's a very different feeling that you get when you're working in this system and pointing to these things and knowing where everything is. I've found that feeling is kind of hard to express if you haven't experienced it yourself.

Now I want to talk a little bit about what constitutes an object. How do objects work?
To start out, we can take a look at that little object in the corner here. This is just a little bouncy ball simulation that I made. [more]

I can bring it up in the inspector. Maybe I can want to duplicate it.
I point to somewhere on that far wall over there, and hit “duplicate”, and draw a little bounding box.

Now we have a copy of that object up there.
I could change that copy. Say, I want forty balls instead of twenty.
I change the code and save it. Now I have different code running up there.
So, the objects don't really care what physical machine they're running on. They don't care what projectors and cameras are involved in running them.
The entire room is kind of a unified computational space, and all the objects can see and respond to each other, no matter where they are.
Now, let's try blessing an object from scratch, so you can really see how these things are built up.
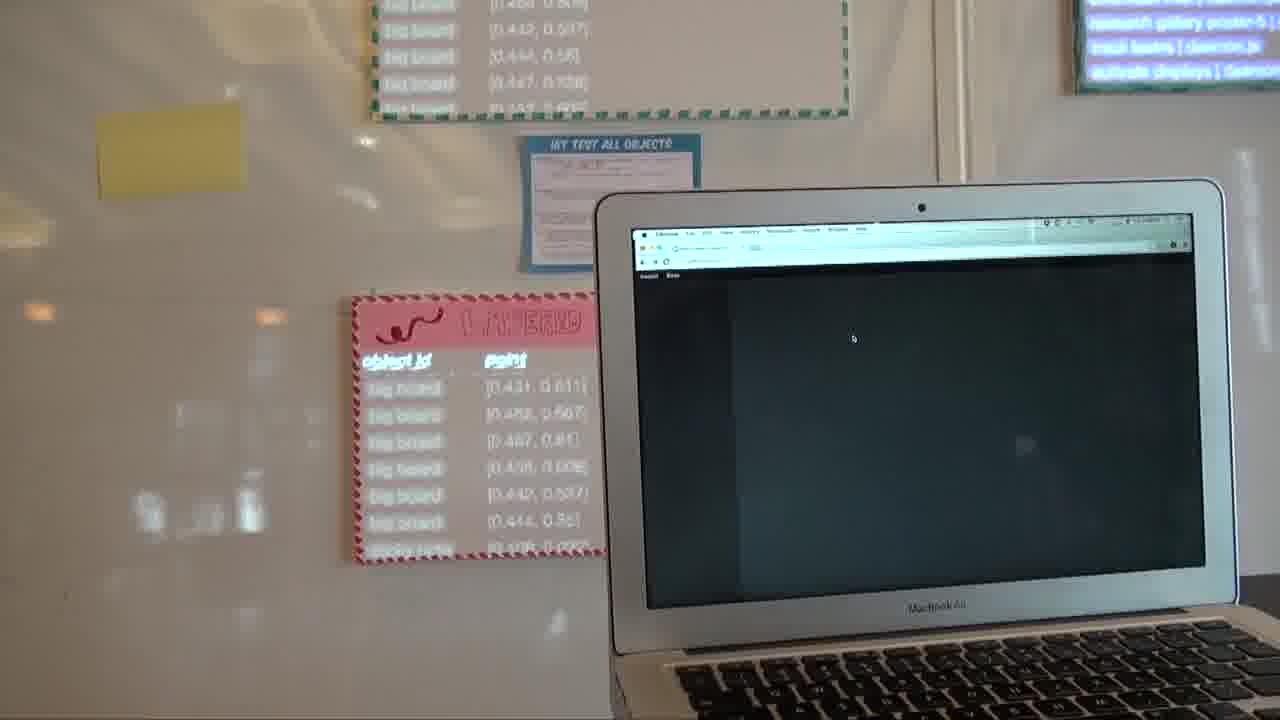
I just put a sticky note on the whiteboard, and now we want to bless it. That means pointing at the four corners, like so.
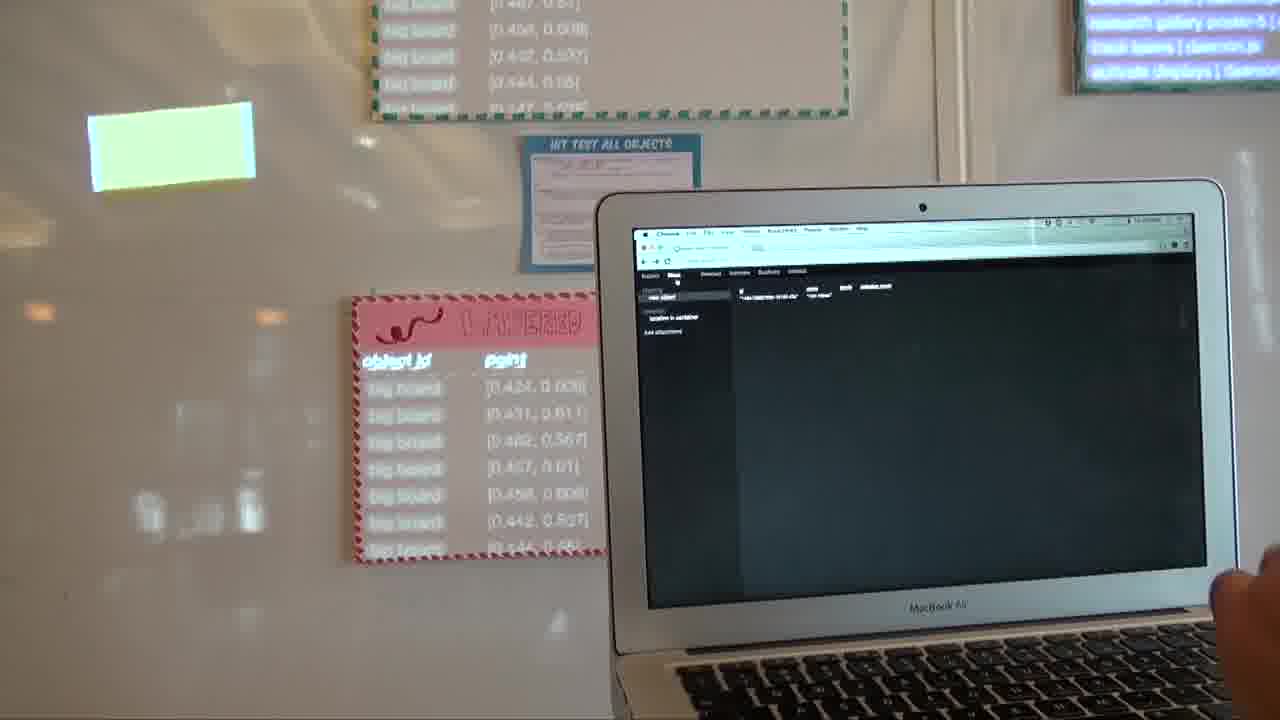
Blessing does exactly two things. One is that it creates an identity for the object. So now it has a unique ID and we can give it a name, like that.
And it also gives it a location attachment. In this case, it's a “location in container” attachment. That says where it is within the Bigboard.
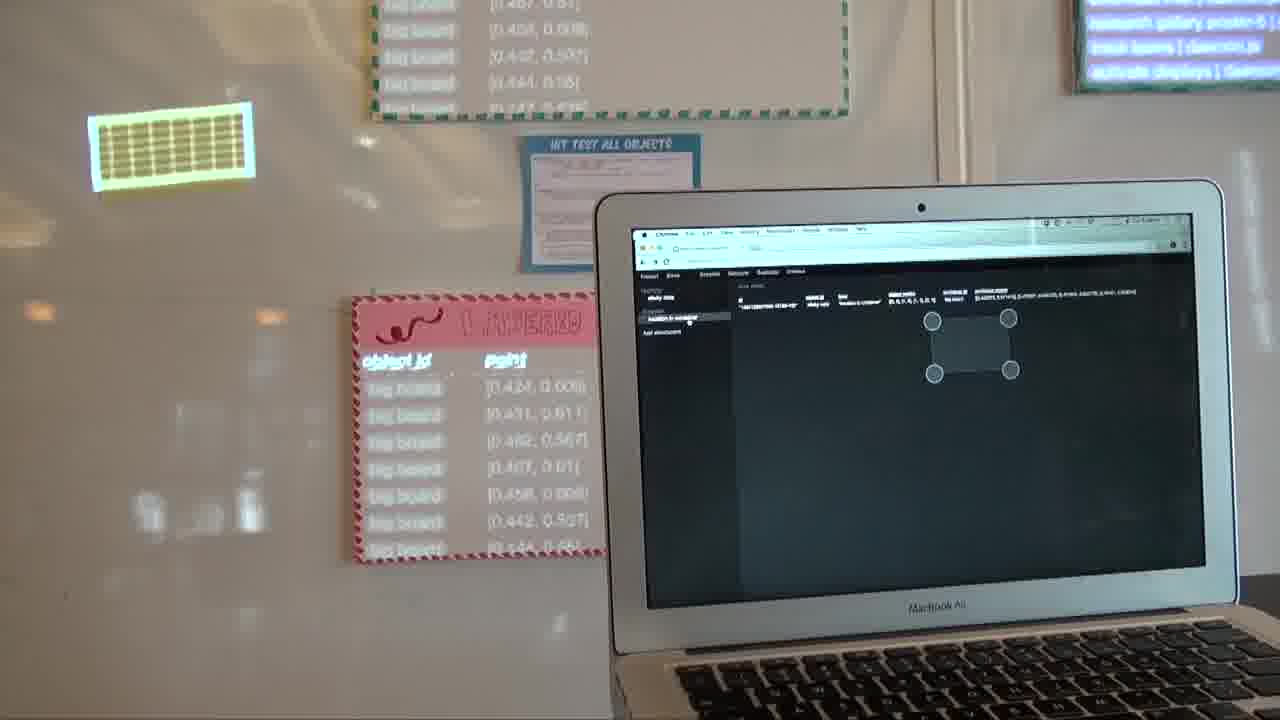
And if we were to inspect Bigboard, you'd see that it has location attachments, “location in camera” and “location in display”, which say where it is within some particular camera and some particular projector space.
So, the model here is physical objects with virtual attachments.
Some of the other things we can attach to objects are data.
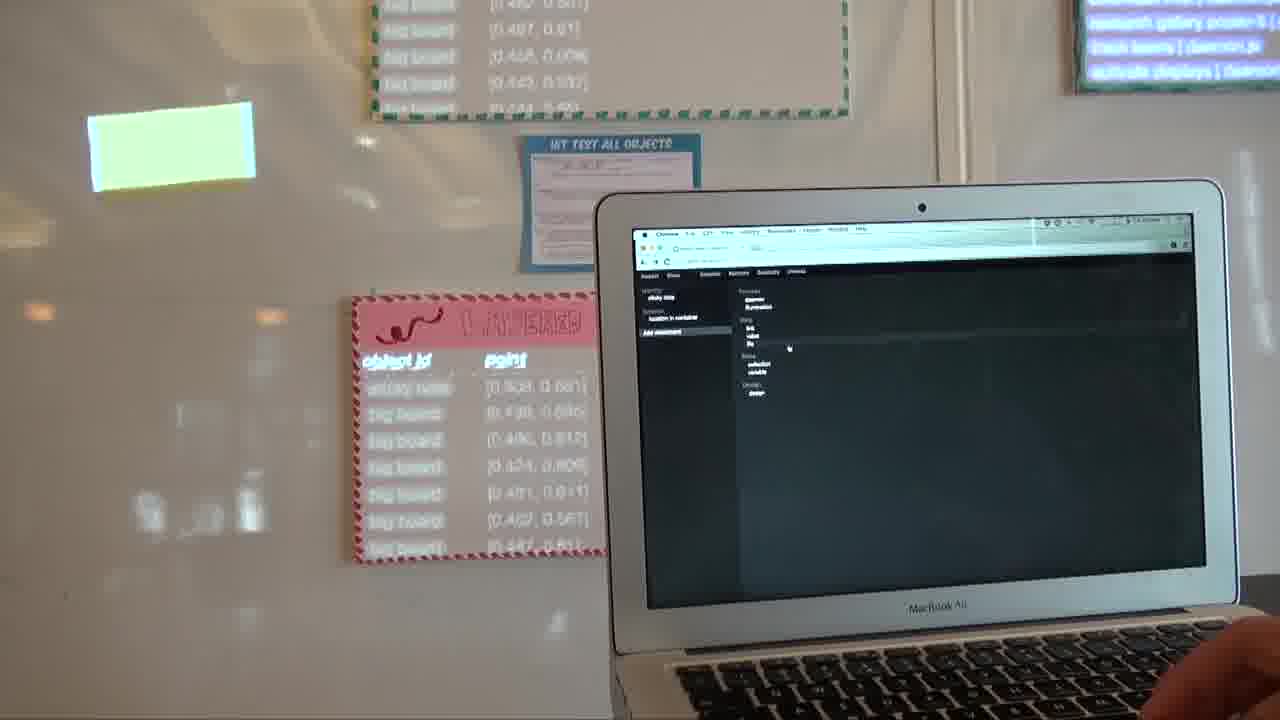
For example, we can make a little text file here.
And now this file is attached to the object. Other objects can see it. And we can even link to it on the web.
So, this is a way that objects can present web interfaces to themselves if they want to. You just attach an HTML file to them, and then you inspect them and link off that file.
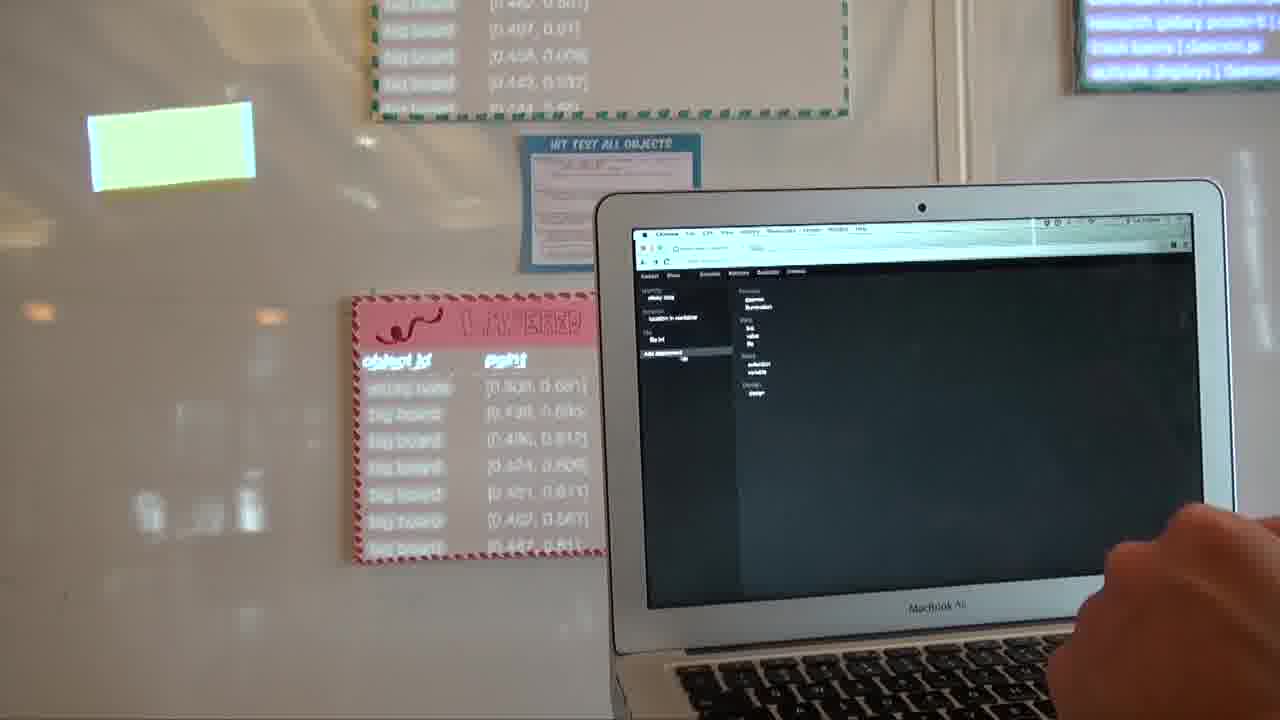
We can add state to an object. The objects on Bigboard, for example, have collections attached to them.
We can also just add a simple variable, like so. And then other objects can see this variable and respond to it and whatnot.
And we can add code to an object.
I attached an illumination. The object is selected right now, so this is currently running.
For example, I might say “backgroundColor = red”.
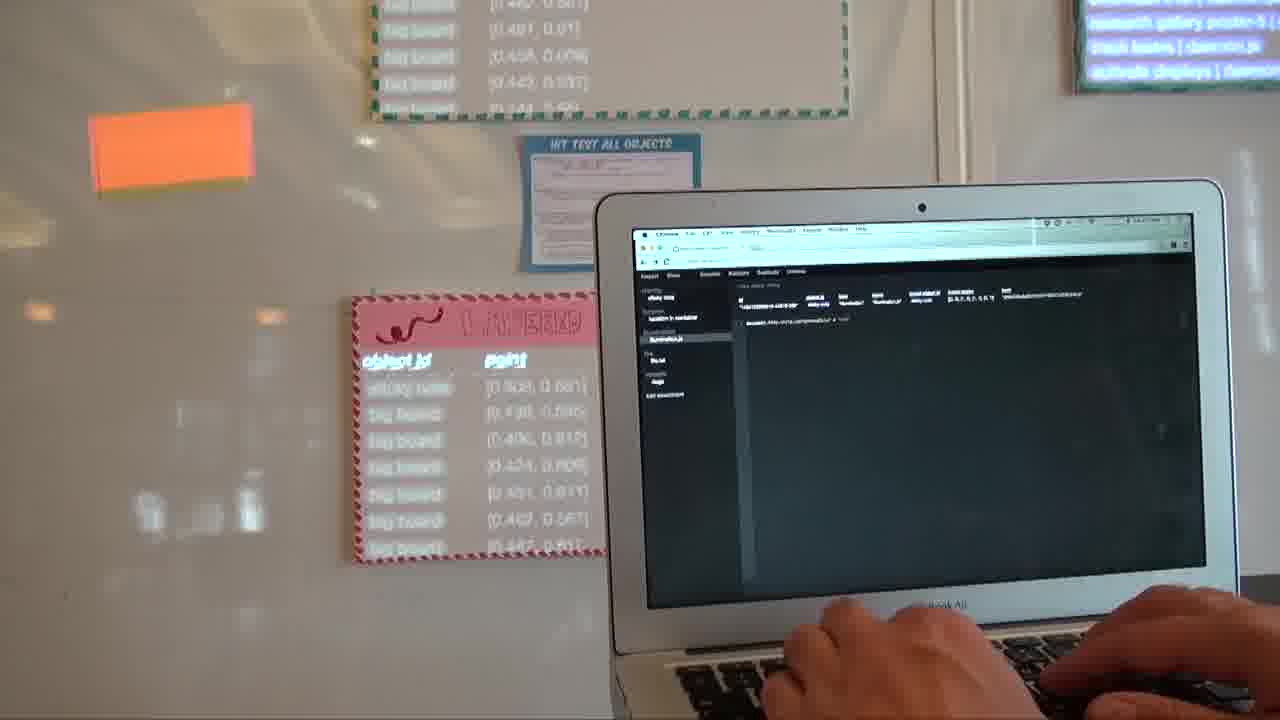
It looks orange right now because it's red being projected on top of a yellow sticky note.
And we could, say, add some text.
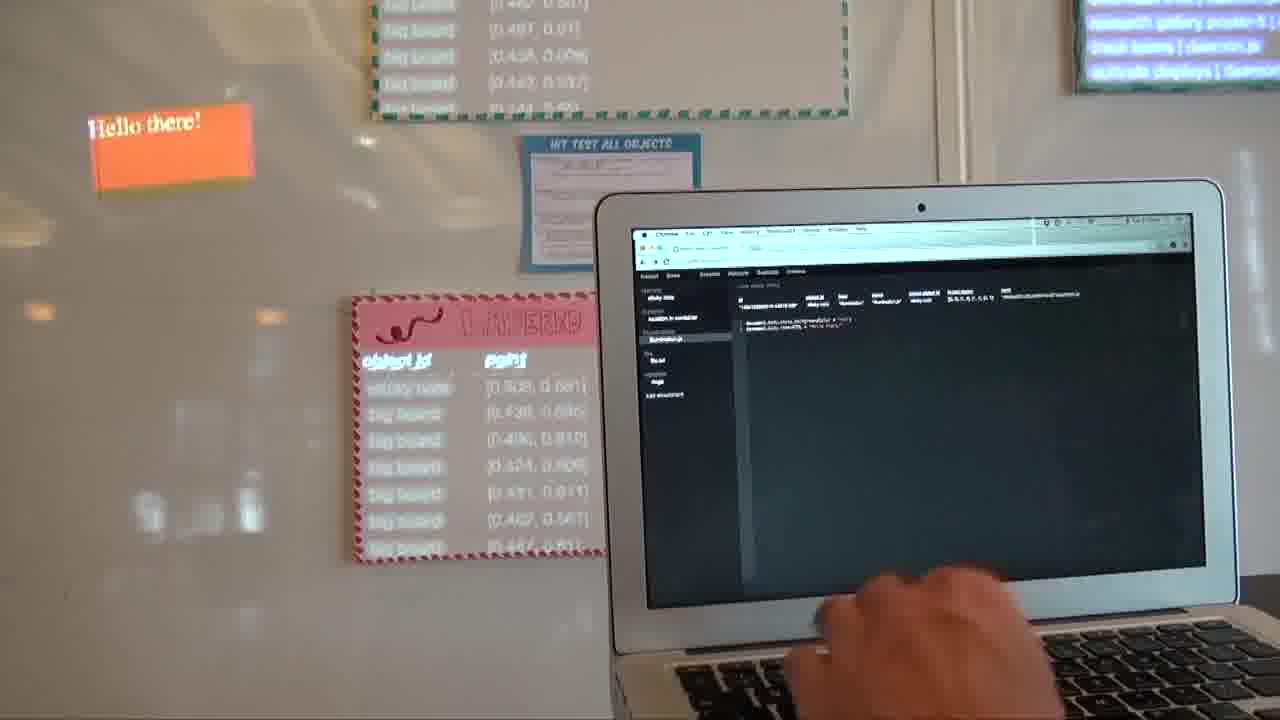
Now, say we want to make it respond.
When the laser goes inside this object, we want it to turn green instead of red. How do we do that?
Well, as a human observer, you notice that when the laser goes inside the object, that object appears here in the “lasered objects” collection.
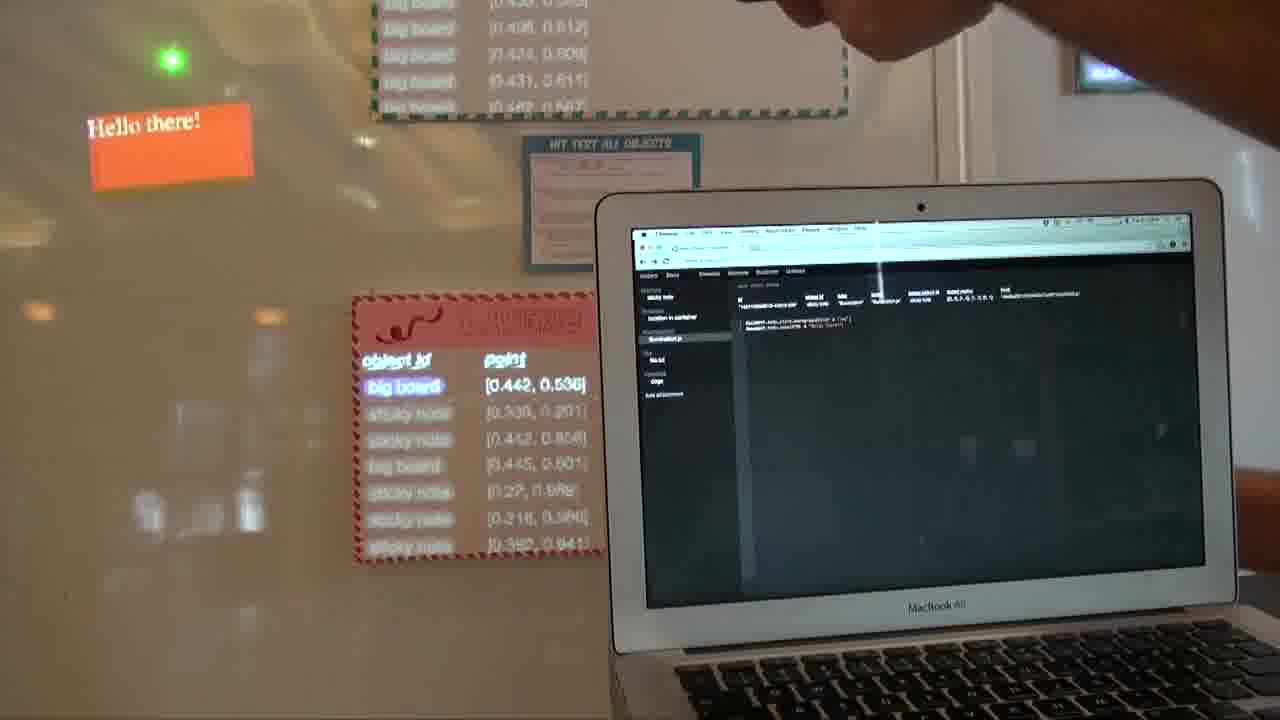
You write the code exactly the same way, to notice exactly what you're seeing. Which is, when I'm inside this collection, I'm going to turn green instead of red.
I'll paste in a little bit of code to do exactly that. Basically, watch the “lasered objects” collection, and if I'm inside it, then I turn green instead of red.
Let's try it.
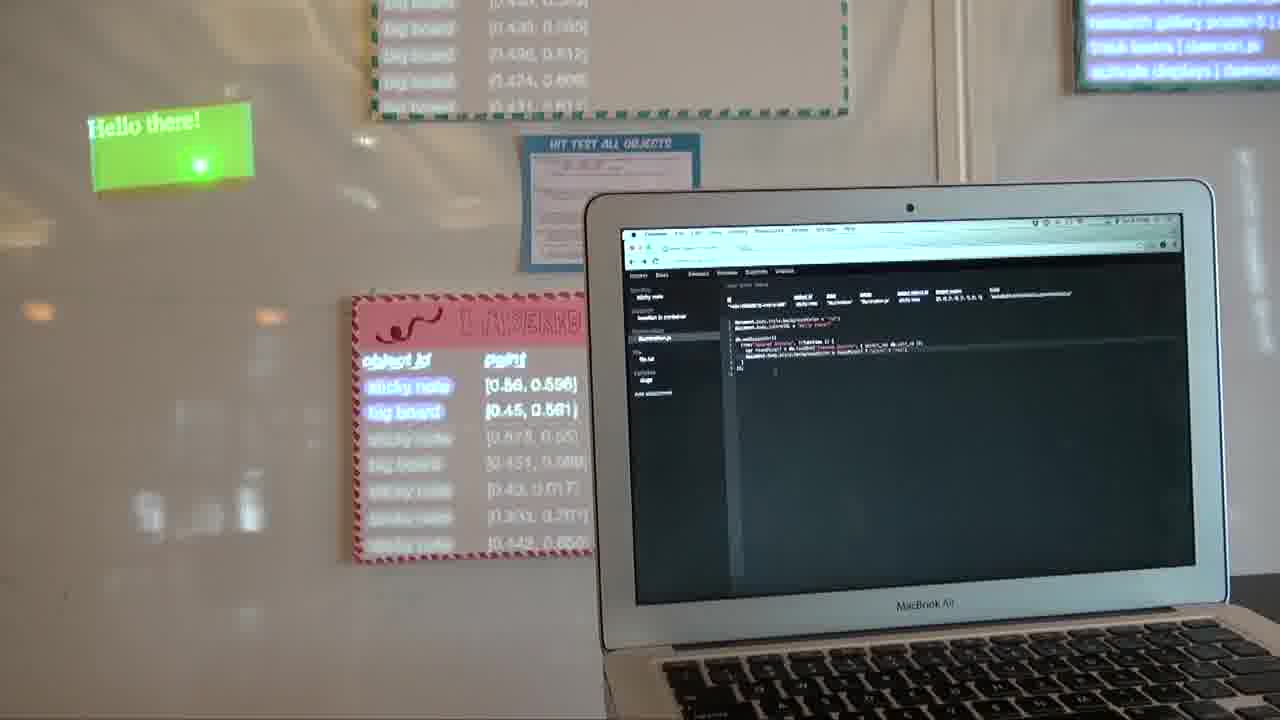
The laser goes inside. It turns green instead of red.
That's what you get from having this kind of total visibility. What the object sees and what the human sees are exactly the same thing.
So, when you're writing the code, you don't have to imagine this data over here in your head. You're seeing the data, and the code is seeing exactly the same data. You can write the code accordingly.

There's one more thing that I want to mention. You saw that you could attach state to objects, in the form of collection attachments and variables.
That's, in fact, the only form of state in the system. All state has to live on some physical object, where you can get to it and point to it and see where it is.
That's even true for the object metadata, which defines what the objects are in the first place.
Over here, this is the identities collection.

This has all the identities for all the objects in the room.
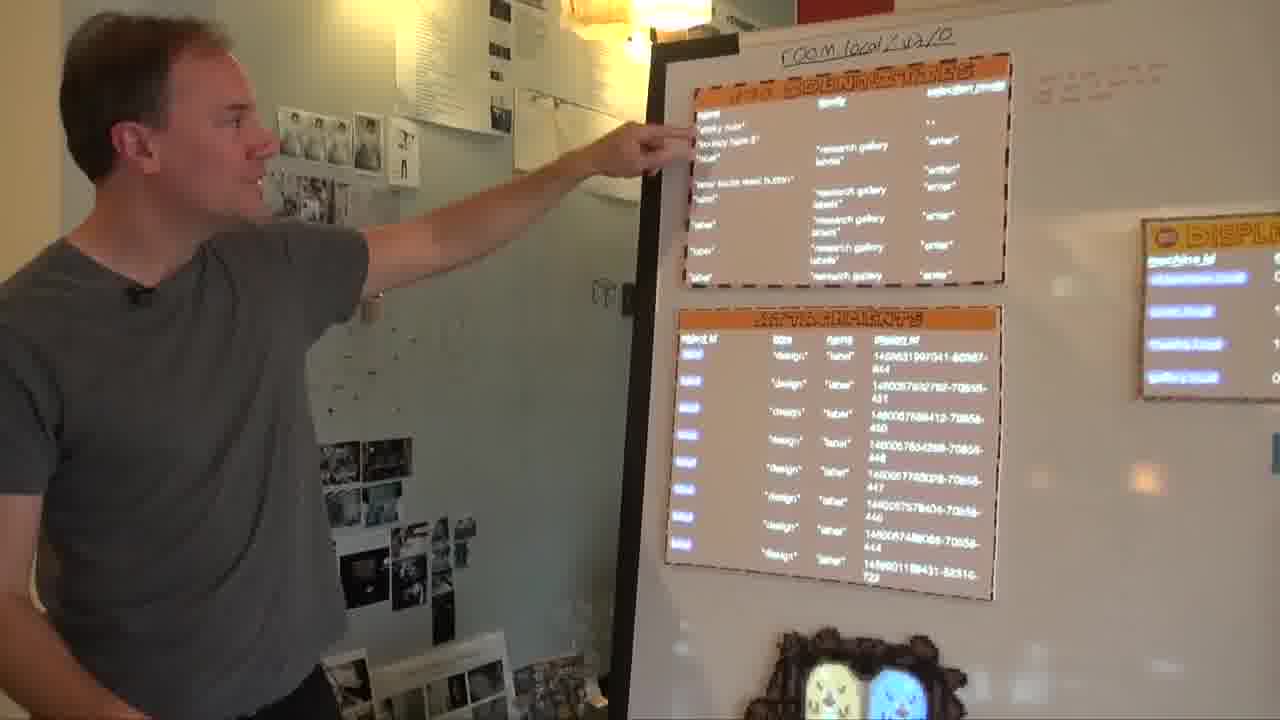
This here is the sticky note that we just blessed. Here's its identity.
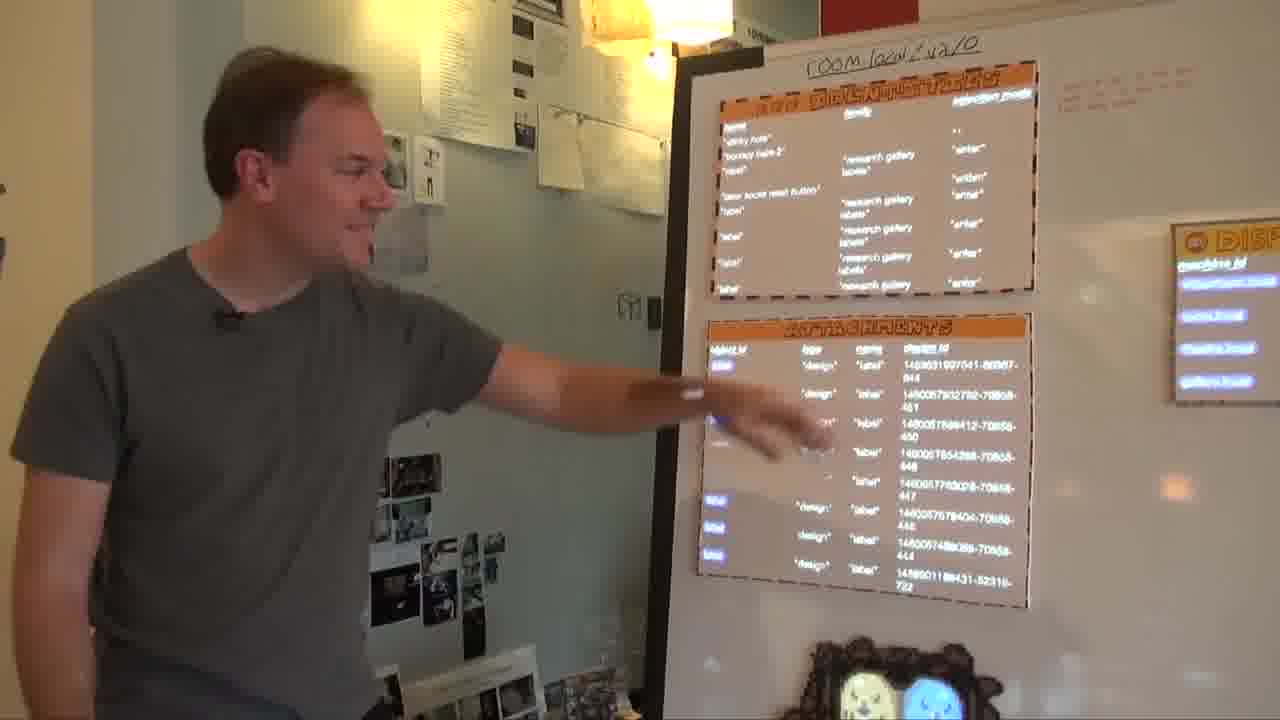
And here's the attachments collection, which have all the attachments for all the objects, which make them what they are.
So, the meta system is just as physical and spatial as everything else.
And these are just ordinary objects. You can bring them up in the inspector. You can edit them.
And other objects can see these collections and edit them as well. So anybody can bless new objects and change object structure.
There's no special privileges, and everything is equally visible.
Conclusion
The Hypercard in the World project originated with the yearning to see context.

Initially, we just wanted to see all of our emails, and see all of the projects we had done.
But we also wanted to see the structure of the book we were reading, or the structure of the video we were watching, or the structure of the system we were building.
And you don't need computation to see context.

A well-designed poster will get you a long way, as long as you give it the space that it needs.
People have been representing and communicating ideas using physical media for a very long time.

On pages, posters, shelves, walls, panels, game boards, models, spaces...

These things all take however much space they need.

They're persistent, stable, tangible, easily handled and organized.

They're all multiplayer by default, and establish common ground among everyone present.

Here's the central question that Hypercard in the World provoked.
If we believe that computation can enhance our ways of representing and communicating ideas, what form should that computation take?
Does it really mean replacing physical things with an array of pixels?
Or can we just sprinkle computation as needed on top of these wonderful physical things?
Because, if a well-designed poster gets you a long way, a well-designed poster with just a few lines of code opens up whole new worlds.

Compare this to conventional computing today, in which browsers and operating systems essentially try to simulate a kind of virtual world of text and images that you click on.
The computational complexity of doing this is overwhelming, which means that almost everyone has to be a user of these systems rather than creating computational systems for themselves.
And doing it this way never fully works.
Hypercard in the World suggests a way of moving forward with computation that is accessible and human scale.
Later work
Hypercard in the World was a research prototype. It served its purpose of giving us a glimpse of this new way of using computation to represent and communicate ideas.
And at least for me personally, I felt like I had been freed from the prison of the computer screen, and I had no intention of going back.

Like any good prototype, Hypercard in the World brought up a lot of questions that it couldn't answer. Over the next year or two, the group made further prototypes to explore these questions.
One big question is about using our hands.

Laser pointing is okay if we're referring to things far away. But when objects are up close, how can we arrange and manipulate them directly with our hands? [1] [2] [3]

How can we work together in a shared space with everyone seeing what everyone else is working on? [more]

How can we create programs without a computer screen? [1] [2]

And if we're able to move objects with our hands, could objects even be programmed to move themselves? [1] [2]

All this work culminated in Realtalk.

Like Hypercard in the World, Realtalk is a computing environment in which programs run on physical objects. [more]
But it doesn't just give us a glimpse of a new world. It lets us actually live in the new world.

Realtalk is completely built in itself, and we do all of our day-to-day work in it.

It's been years since I've written a computer program inside a screen, and I don't expect to ever do so again.

Dynamicland is a community space we formed around Realtalk, in which hundreds of people of all kinds — artists, scientists, teachers, students — used Realtalk to represent and communicate their own ideas. [more]

And in a close collaboration with a bioscience lab, we've been doing real cutting-edge biomolecular design, using computational pieces of paper, posters, game pieces, playing cards, test tube racks, and even still, laser pointers. [more]

You can find more information about this later work on the Dynamicland website. [more]

Hypercard in the World was one early prototype pointing the way.

Thank you for watching.
