[journal] [journal] [journal]




What I'm trying to get at with this whiteboard feels important, but it's too hazy for me to articulate yet. I'm going to try anyway. Maybe just so I can reuse the whiteboard.
In the left columns, I've thought about some of the projects we've discussed, and identified some things that might be modeled as "objects". There are a variety of objects, and different objects have different physical capabilities (which I've also tried to list).
What I'm trying to think about here is not just the ways in which the objects are different, but also the ways in which they are the same -- what is a generic "object model" that fits all of them, and allows a poster and a binder page and a robot to all be represented uniformly as "objects" (and see each other as objects) but also can accommodate what makes each of them special.
One thing I'm thinking about is how certain objects need to be in certain environments to exercise their capabilities. A magnetic token needs to be on the x-y table in order to move itself. A token with a fiducial on its underside needs to be on a transparent table with a camera underneath. Many things will need to be in view of some camera. In general, an object may need to be situated in a particular sensing or actuating environment in order to be active. I think that's completely fine -- we're not necessarily trying to "hide the magic" and pretend that a piece of foamcore is actually alive; it's fine to see the strings on the puppets -- it's just something that needs to be reflected in the capability model. (Perhaps capabilities have "scopes". (There should be clear visible indications when an object is out of its useful scope.))
Here are the capabilities that came up, and some technologies that might implement them.
I used "drawn on" to mean "drawn on by an object", i.e. what we used to call "illuminated" (or "projected on"). It's confusing terminology and might not last, but I like that an object could be
drawn on by a person (with a pencil), or
drawn on by an object (with a projector or screen), or
moved by a person (by hand), or
moved by an object (robotics, x-y, etc).
I got the impression that a small set of capabilities could cover most of the envisioned use cases. With a couple of object tracking methods, targeted high-resolution projection, and maybe targeted high-resolution camera+OCR, we can do most of what we've thought of doing, and hack around the rest. It's well within the bounds of short-term feasibility. I'm interested in a capability model that allows us to start with a small set of core capabilities and gracefully expand as needed.
This next bit is about the physical world as "common ground" to avoid silos. It feels very important, but the thoughts are extremely early/hazy right now and I don't have the right words yet.
The text at the bottom says:
Even though these objects appear together on a screen, they exist in separate fictional realities. Outside of the Sketch environment, a Sketch object has no existence whatsoever.Our goal, instead, is an object model where all objects have an undeniable common ground in the physical world. (Augmented with a simple and minimal "virtual field".)In a unix system, the filesystem (augmented with a minimal set of system calls) provides a common ground. Programs can be written in any language and use any form of computation, but they all agree on what a file is.Likewise, we'd like a common ground of physical reality, while enabling people to experiment with objects that run imperative code, and other objects that send messages, and objects that pull like spreadsheet cells, and objects that follow local rules like ARK, and objects that try to satisfy constraints like ThingLab, and objects that reflect a data model like MVC.That is, we need to be able to try out different models of computation without creating insular "alternate realities", because all of these objects exist together in the one physical reality.This means there needs to be a decoupling between object existence and object behavior. All objects can see other objects and agree that they're there, in the same way that people see the objects and agree that they're there.But the meaning of an object, or configuration of objects, is left to local interpretation. In the same way that different people will interpret the same scene in different ways, and take different actions, different interpreters could interpret a scene in different ways, and take different actions. Perhaps some actions will superimpose, and some will conflict, just like actions by people.
This is a reaction to the screen-based tradition of creating incompatible realities in order to provide objects with different kinds of behavior. (Apps and web apps and yes Smalltalk images -- but even within Smalltalk, you can't apply Thinglab constraints to an ARK object, etc.)
I've been thinking about the unix analogy a lot in the last few days. In unix, the objects (files) are "dumb". Their meaning comes from how they are interpreted (by programs). One benefit of this is that it doesn't impose an "institution" on a person. Given a text file, you might write a Python script to process it, I might write a Perl script, someone else might grep, and someone else might just go through it manually in emacs. By contrast, given a Photoshop file, now you're in Photoshop. Given a FileMaker database, now you're in FileMaker.
Likewise -- you could make Glen's video coaster environment by attaching code to the coasters to make them "smart" "objects". Now you have an app. Alternatively -- and this really struck me -- I can make a binder with my "coaster interpreter", and Glen can make a whiteboard with his own "coaster interpreter", and whichever one we bring over into that context ("in scope"?) will determine how the coasters behave. The coasters themselves are "dumb"; they are given meaning by my interpretation, or Glen's interpretation. (In the same way that you might run a text file through one program or another.)
This feels like it helps move away from the "designed experience" thing that I want to move away from. The coasters are no longer "user interface elements"; they are material. How I use them is up to me. They have no built-in preconceived notions of how they should be used. I can bring in preconceived notions in the form of a binder / program (and I can modify that to taste), or I can build up my own interpreter, or combine a few together. I am not living in a world that some designer made for a mass market. (Connections here to conviviality.)
I'd like to think more carefully about the benefits of (real / Alan) objects, and how we can incorporate these benefits into this less-object-oriented way of building. Smalltalk and unix are strange bedfellows, but I think they are both viable inspirations for this system.
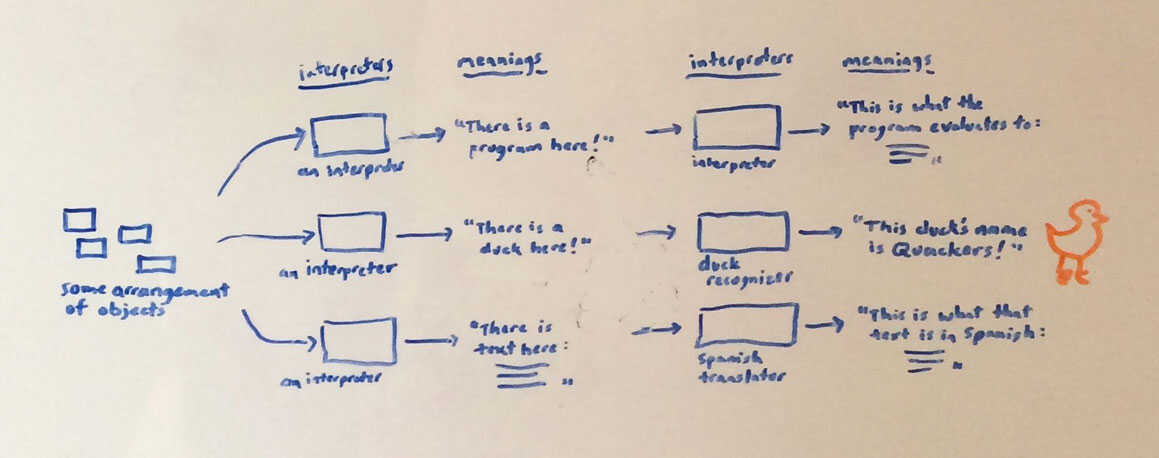
This last bit is kind of silly, but it's coming out of a (again, still very vague) theory of "interpretation" that's been slowly coalescing. I think the metaphor is that, when a person looks at a scene, the meaning of the scene is not inherent in the scene itself, but comes from the person's interpretation. If everybody had to agree on the meaning of everything in the world, the world wouldn't work.
(Apps work because they create an isolated fictional world where everything has a meaning determined by the designer. That's what I don't want.)
The thought is that "interpretation" seems to be a pretty general concept. A text can be interpreted as a program, and executed. An arrangement of tokens on a desk can also be interpreted as a program, and executed. Or interpreted in some other way for some other purpose. A laser shining on a coaster can be interpreted as a request to play a video. At least when my interpreter is in effect. Glen's interpreter might assign a different meaning to this scene, or no meaning at all.
Two things that seem particularly interesting are:
- the possibility of a single "interpretation framework/concept" that covers all these cases, where interpreting code and interpreting an arrangement of tokens and interpreting a laser shining on a coaster are simply seen as "interpretation"
- continuous interpretation. Like a person, the system is continuously examining the scene and trying to interpret a meaning from it. Move a token enough that the meaning changes, and everything responds immediately and automatically. Or change a line of code, same thing. Maybe impractical, but I'm kind of taken by the thought of "source code" literally being the physical writing in the world, and nothing more -- continuously being camera-captured, OCR'd, and executed. (We would need to build in a notion of "object permanence" so the system doesn't stop working when the lights turn off. Or maybe it should?)
Glen drew Quackers.
Maybe this helps suggest why I'm uncomfortable with the name "Room OS". It shouldn't be that our room is a magical sacred space that grants meaning and behavior to the objects in it. The objects themselves are the focus, either because they have behavior built into them, or they are perceived as having meaning by an interpreter (which is itself an object). Ideally, you'll be able to bring interpreting objects anywhere and they'll interpret whatever they see there, and bring behaving objects anywhere and they'll behave appropriately with their neighbor objects. (Where "anywhere" might have to be an environment that offers sufficient capabilities, at least for now.)