Wow! I had always known intellectually why speech recognition was hard, but these interfaces really make me appreciate how complicated it is, even if you get the phonemes right! Something about hearing the tiny samples of audio and seeing the alternate interpretations really hit me. Neat.
On Thu, Jun 25, 2015 at 9:19 PM, Bret Victor wrote:
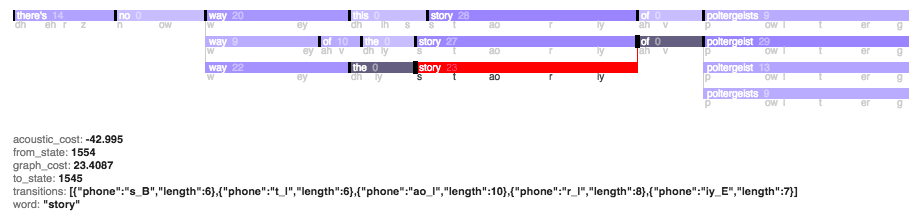
I was looking at your "compact lattice" JSON and was curious to see the entire graph, so I made this visualization, derived from yours:The black boxes are nodes (states) and the purple bars are edges (words). The phonemes for each edge are below it.Mouse over things, or click-and-spacebar to start playback.On Jun 25, 2015, at 12:06 PM, Robert M Ochshorn wrote:
…coming back to Edlund on analog versus digital.
I’ve been trying to extract meaningful intermediate data from Kaldi, and now have a pruned “compact lattice” data structure in JSON and in a form that I mostly understand. This visualization does not yet show the dependencies/edges (which are one of the most important parts!) but I’ve already gained a lot of insight by studying it.
<Screen Shot 2015-06-25 at 11.58.04 AM.png>
On the top are possible phonemes, and on the bottom possible words, all temporally aligned. I had suspected that changing speakers was screwing up accuracy, but I don’t think I appreciated just how much a difference it makes. This video shows me scrubbing through a transcription where the speaker changes, and then switching to a recording that was trimmed when the second speaker (Edlund) starts. What’s amazing to me is how subjective/contextual even the phonemes are!
Live prototype trained on #1 and #2.
The UI tries to be fairly “alive.” Words/phonemes play when you hover over them, and the “global” razor waits for clicks (and space-bar). Still, I’m haunted by clicks… cross-fade took away the precision I wanted, and it’s so much of a pain in the Web Audio API to get/mess with sample-level data. To be continued…
-RMOOn Jun 18, 2015, at 4:01 AM, Robert M Ochshorn wrote:
Dave,
I didn’t fully appreciate your choice of subject until now. Of course the transcript is the “digital” form of “analog” speech!
Here we are:
<Screen Shot 2015-06-18 at 3.35.25 AM.png>
It’s by no means perfect, and I think there’s a lot I can do within Kaldi to improve accuracy (I’m pretty sure that I’m messing up the “endpoint detection,” I should be able to automatically figure out when the speaker changes and swap/train models, and I still only have the faintest clue how to make proper use of the lattice structure internal to all of this, &c &c &c), …
… but a week & 237 lines of horrid C++ (plus a little python) later, I can extract decent word-aligned transcripts from files of any length (or live from a microphone). Phonemes, alternate possibilities, and confidence metrics are all forthcoming.
Apparently if you store a phoneme-related data structure, you can write transcript search that is robust to mis-transcriptions and in addition to text search, it can work from voice (i.e. without a textual intermediary).
Figuring out how to constrain to a “command vocabulary” should be possible, but will take a bit more wrangling with Kaldi’s epic codebase[0].
Onward,
R.M.O.
[0]
Here’s what we’re up against—hundreds of thousands of lines of code, in 16 languages:
GATORADE:kaldi rmo$ cloc .
3418 text files.
2866 unique files.
558 files ignored.
http://cloc.sourceforge.net v 1.62 T=10.62 s (232.5 files/s, 41228.3 lines/s)
--------------------------------------------------------------------------------
Language files blank comment code
--------------------------------------------------------------------------------
C++ 767 25827 26574 135668
Bourne Shell 1006 21475 19861 78718
C/C++ Header 290 12619 20220 42100
Perl 246 3677 5338 20927
Python 64 1545 2342 6527
Visual Basic 1 620 0 4082
CUDA 2 520 666 1693
Bourne Again Shell 10 264 245 1290
make 46 499 79 1035
C 1 95 49 859
HTML 2 102 13 724
Java 10 251 140 708
MATLAB 3 55 79 191
ASP.Net 19 3 0 83
awk 1 5 16 20
sed 1 1 0 10
--------------------------------------------------------------------------------
SUM: 2469 67558 75622 294635
--------------------------------------------------------------------------------On Jun 11, 2015, at 8:57 AM, Robert M Ochshorn wrote:
WOW!
GATORADE:speech-data rmo$ ~/src/found/kaldi-trunk/src/online2bin/online2-wav-nnet2-latgen-faster --do-endpointing=false --online=false --config=nnet_a_gpu_online/conf/online_nnet2_decoding.conf --max-active=7000 --beam=15.0 --lattice-beam=6.0 --acoustic-scale=0.1 --word-symbol-table=graph/words.txt nnet_a_gpu_online/smbr_epoch2.mdl graph/HCLG.fst "ark:echo utterance-id1 utterance-id1|" "scp:echo utterance-id1 03-20.wav|" ark:/dev/null
/Users/rmo/src/found/kaldi-trunk/src/online2bin/online2-wav-nnet2-latgen-faster --do-endpointing=false --online=false --config=nnet_a_gpu_online/conf/online_nnet2_decoding.conf --max-active=7000 --beam=15.0 --lattice-beam=6.0 --acoustic-scale=0.1 --word-symbol-table=graph/words.txt nnet_a_gpu_online/smbr_epoch2.mdl graph/HCLG.fst 'ark:echo utterance-id1 utterance-id1|' 'scp:echo utterance-id1 03-20.wav|' ark:/dev/null
LOG (online2-wav-nnet2-latgen-faster:ComputeDerivedVars():ivector-extractor.cc:180) Computing derived variables for iVector extractor
LOG (online2-wav-nnet2-latgen-faster:ComputeDerivedVars():ivector-extractor.cc:201) Done.
utterance-id1 there's no way the story of poltergeists could be told without the use of visual effects and that's worth visual effects supervisor richard edlund and industry like magic into the picture see the whole thing about an hour and a younger thinking who i was forced to read a unfair and give her the is the reason why cooper
LOG (online2-wav-nnet2-latgen-faster:main():online2-wav-nnet2-latgen-faster.cc:272) Decoded utterance utterance-id1
LOG (online2-wav-nnet2-latgen-faster:Print():online-timing.cc:55) Timing stats: real-time factor for offline decoding was 1.02339 = 20.4679 seconds / 20 seconds.
LOG (online2-wav-nnet2-latgen-faster:main():online2-wav-nnet2-latgen-faster.cc:278) Decoded 1 utterances, 0 with errors.
LOG (online2-wav-nnet2-latgen-faster:main():online2-wav-nnet2-latgen-faster.cc:280) Overall likelihood per frame was 0.222644 per frame over 1998 frames.
That’s the first 20 seconds of Dave’s audio file, transcribed with kaldi, using a pre-computed GPU-based modern (neural net) model, trained on the CALLHOME audio corpus.
This seems very promising!
Onward,
R.M.O.On Jun 2, 2015, at 6:43 PM, Dave Cerf wrote:I also wondered (but didn’t look around much) how to easily transcribe the interview: is there an equivalent to OpenCV for speech? I know the Mac has built-in dictation, so maybe I could wrangle that somehow.
There’s an insidious, awful, project called “pocketsphinx" that shows up everywhere you go looking for open source speech recognition.
I’ve always puzzled over why sound seems to be a less explored perceptual channel than the visual. On some level, it seems obvious why, but then I puzzle at the obviousness of it. You could say that, like all the other senses (except sight), sound is invisible, and so it is harder to deal with. I suppose lack of vision (the literal kind) is an immediate problem from the moment you get out of bed, whereas lack of hearing is largely a problem of communication in a speech-dominated world (though becoming less so with the prevalence of email, texting, video chat, etc.).
Here is a brief list of animals who are unlikely to contribute to the pocketsphinx project. But vision seems to be compensated for more by touch and smell than hearing.
Regarding the transcription results, it seems less useful to judge them by accuracy than by how amusing the results are. Pocketsphinx isn’t even very funny. I decided to route the audio from my laptop directly into the Mac dictation (results below), which actually works. The text feels more like plausible speech, but it still isn’t great (and Edlund’s voice is quite clear, though there are a number of stutters—but that’s typical). Also, because I used continuous dictation, there is no punctuation and the sentences run on forever. The process was also slow (real time) and locked up the rest of the computer.
I also converted the text back to speech, just because. I couldn’t even get past listening to the first minute. The lack of punctuation is probably the deal breaker here.
<03_AC_Podcast_Poltergeist_Excerpts_SpeechTextSpeech.m4a>
Be told without the use of the fax and that's what you look like supervisor Richard and let the dust real like much to the picture girlfriend about him or thinking is that it allows for Sarah and get answer and get that he is the reason I'm trying to bring with one of the actors to a seen for 100 takes as he was waiting for that sound get any to happen in and if it didn't happen is okay with having here until it happened and then I'll send you get this magical thing would happen that would be the thing about computer in Asian is that everything that happens has to be in all actually inserted so it's very difficult for soon get this performance to come pick is you have to and watch allies that sure and get this live now he goes to last text to meet Carol at sucking the tire house or so I can you for the house
Call me but like by plane talk to it all slowly into itself running through the script I come up to this sense in the house in clothes now I got your friend more shows a producer of the show is in a Frank this is a $250,000 this is what I said it says him load not explode exploding is easy in floating is some else to do the whole show to put much is it was like whenever it was like the money shot for the movie I know what some of you might be I was like to ask at let you talk and it'll text a lot shot any better than the weight was actually.I just don't think would look forget if we didn't enjoy things to come to the thing you talking about calling all these walls apart of me I don't know I just mean maybe some some and tell me that they could do that I just think it would look intellectual and we'll talk about it a point to make you just have to call text talk to you cause it isn't it's up to compositing was so difficult just to get red of them that mean we went to the most out rages extremes in order to create master would enable us to get motion blur that that that that made it feel like it was a normal shot and now we have did you housing I am in heaven no but I I I love to do use it on some issues at home and send the old way and and have the incredible give abilities we have no digital compositing and in and in that way I'm I think that that would ride to be in the same situation as shooting movie like old guys today it would be more fun because we've the less limited by the group is list of the phone traffic process mean that the boy traffic process was so mean that the win's a note on these these processes were so difficult and so time-consuming and therefore expensive that you know that I was a big fan of the digital world coming along because I didn't feel like the digital world was going to do a way that I don't think it has done away with the old fashion called techniques it's just a minute and get in give us the 20 to be even more bold in the approaching is your problem