On Mar 4, 2015, at 5:18 PM, Dave Cerf wrote:A few thoughts:• Seeing the laser pointer in action was an emotional moment for me! Pointing at a physical object and having the screen react by “knowing” what video you want to watch is a remarkable step forward. I want this now.Imagine a book (like the one below, which is a real book we used for editing) showing all kinds of moments from a film, and being able to flip through this book and see the corresponding movies on a display screen. The tangibility of such an experience cannot be underestimated. The ability to navigate in cinema space (the screen) from reality (a book, printed pages) would forge fascinating connections between the ephemeral and the static. If we consider the screen/cinema to be a kind of dream space, then this interaction might be a kind of lucid dreaming.
Goodness! I didn’t study your binder closely enough at first to realize that there are dozens of side tabs, but I made this one to start:

The video (hi-res, lo-res) shows me flipping through the binder, and the projection reflecting the current page. Each page is mapped to one of the 482 videos I have from the “Kay Archive” that Yoshiki has been digitizing.
It’s still not completely reliable (~75%), but the biggest annoyance right now (aside from the lack of side-tabs) is that there’s no way to seek within each video. I guess pointing a laser at a thumbnail should jump to that moment in time. Or maybe the thumbnails are mere moments on a smooth continuum and the laser can seek in between, as well? TBD.
This interaction feels magical in a similar way as the lasers do. In this particular instance, I like the way a viewer’s focus is spread between the binder and the screen. Thinking about what to see, and then seeing that thing. The looking up feels natural here, while the looking left felt strange in the Boston set-up. I’m still not completely sure about the underlying rules.
A few reflections/rants below (“dragons,” &c):
1. Alan Kay’s VHS archive is full of wonderful nuggets that pop up when you extract thumbnails or whatever. Consider:
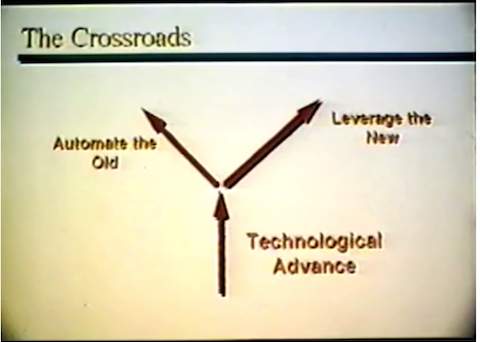
… and even more (enigmatically!) on-point:

The office is real!
I can’t quite figure out where our Room fits into these crossroads, but it seems like an interesting AI/IA-style dichotomy.
2. Computer Vision “best practices” are not to be trusted. Since it’s a field I don’t know very well, I tend to defer to what seems (by OpenCV documentation and Google) to be standard operating practice. This task (finding photographs of known pages) seemed to be a case of object detection. The basic idea is to find noteworthy points (ie. that you’d find again in a differently-sized or rotated image) in the images of the objects and the images from the camera, and then see if there’s a a geometric mapping between the similar points in one image and the other. I got semi-promising results at first using this technique.
Here are all of the point-correspondences between a PNG of the grid and a photo of me holding the grid:

And here are just the point correspondences that made coherent geometric sense:

But when I tried with images that didn’t match, the algorithm still found a way to make it work:

and I realized that most of the tracking points found here were corners of the thumbnails against the white background. I suppose it would be notable to see a form like that in nature.
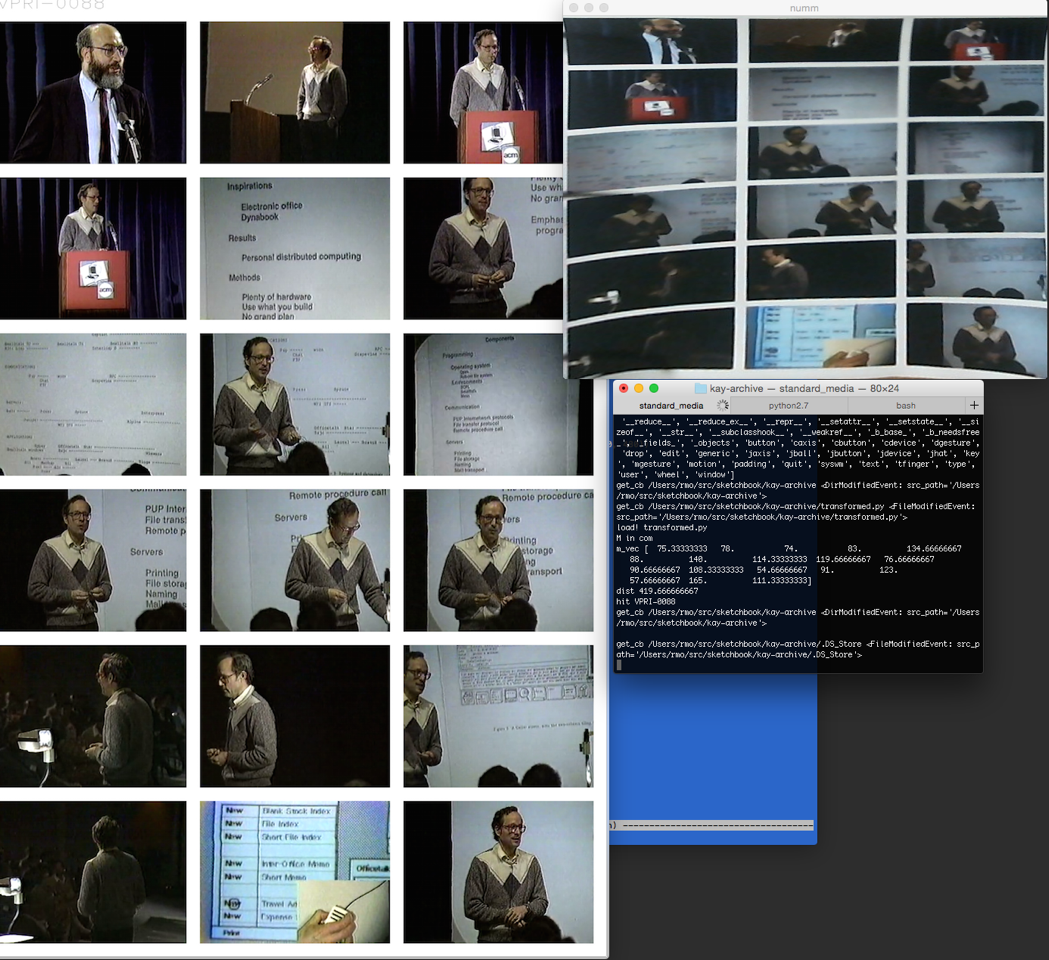
3. “The simplest thing that could possibly work”—I realized while suffering through a funny film this evening—would be to keep the page in a known position, un-warp the camera image to isolate the grid, and then resize the grid so that each thumbnail is a single intensity value. The grids, then, would function somewhat as 24-item continuous-value barcodes. I was so excited when that actually worked. There’s the unwarped camera-image in the upper-right, the terminal in the lower-right telling me we “hit” item VPRI-0088 with a distance of 419, and the quick-view on the left showing that VPRI-0088 really is the same grid:
4. Why is this (ie. defiant blindness) an acceptable attitude for macho computer-vision programmers?

5. We shouldn’t lose track of the limitations of the physical world. No, not an emo call for help, but consider:
• We ran out of printer paper so I didn’t get to print out the whole binder and I couldn’t see 4/5 of the archive!
• I needed to buy a special tool in order to press holes in the paper and fit them into the binder, and then it was a repeated gesture to apply these holes. As point of fact, the shopping and hole-punching had enough novelty to keep me interested, but precisely because it’s not my normal MO. On the other hand, we’ve talked before (w/r/t film industry tooling) about Good Jobs for the Good Intern, and these would certainly fit that bill…
• Sometimes the printer prints a little funny and leaves rainbow dust on the edges of the page.
So much of the move to the cloud and to the rectangle are supposedly to “fix” problems/hiccups like the above. I can see much promise in these hybrid interfaces, but where’s my reprogrammable matter?
• “Whenever you’re ready”: this is the gentleman’s way of saying “action!”

R.M.O.
On Mar 4, 2015, at 2:45 PM, Robert M Ochshorn wrote:For the record, here is a short video of the installation in action.All of the new CDG installations look great! Can’t wait to be back in the mix.RMOOn Feb 28, 2015, at 4:56 PM, Robert M Ochshorn wrote:back to the gallery and make some proper documentation