[notes and mockups on representation of room system state] [rather long] [possibly interesting]
The room system has a database, which maintains both the static and dynamic state of the system. Processes are coordinated not by direct communication ("messaging" metaphor), but by adding items to the database and observing changes to the database ("responding to the environment" metaphor).
Most activity thus tends to be reified as nouns ("creating a (persistent) laser object") rather than verbs ("calling a beginLaser function"), which provides the opportunity to design human-understandable and manipulable representations of these nouns, and thus the system state.
Currently, there is a database view ("BigBoard") which shows the all of the items of each type, updated in realtime, and allows items to be created or edited "by hand".
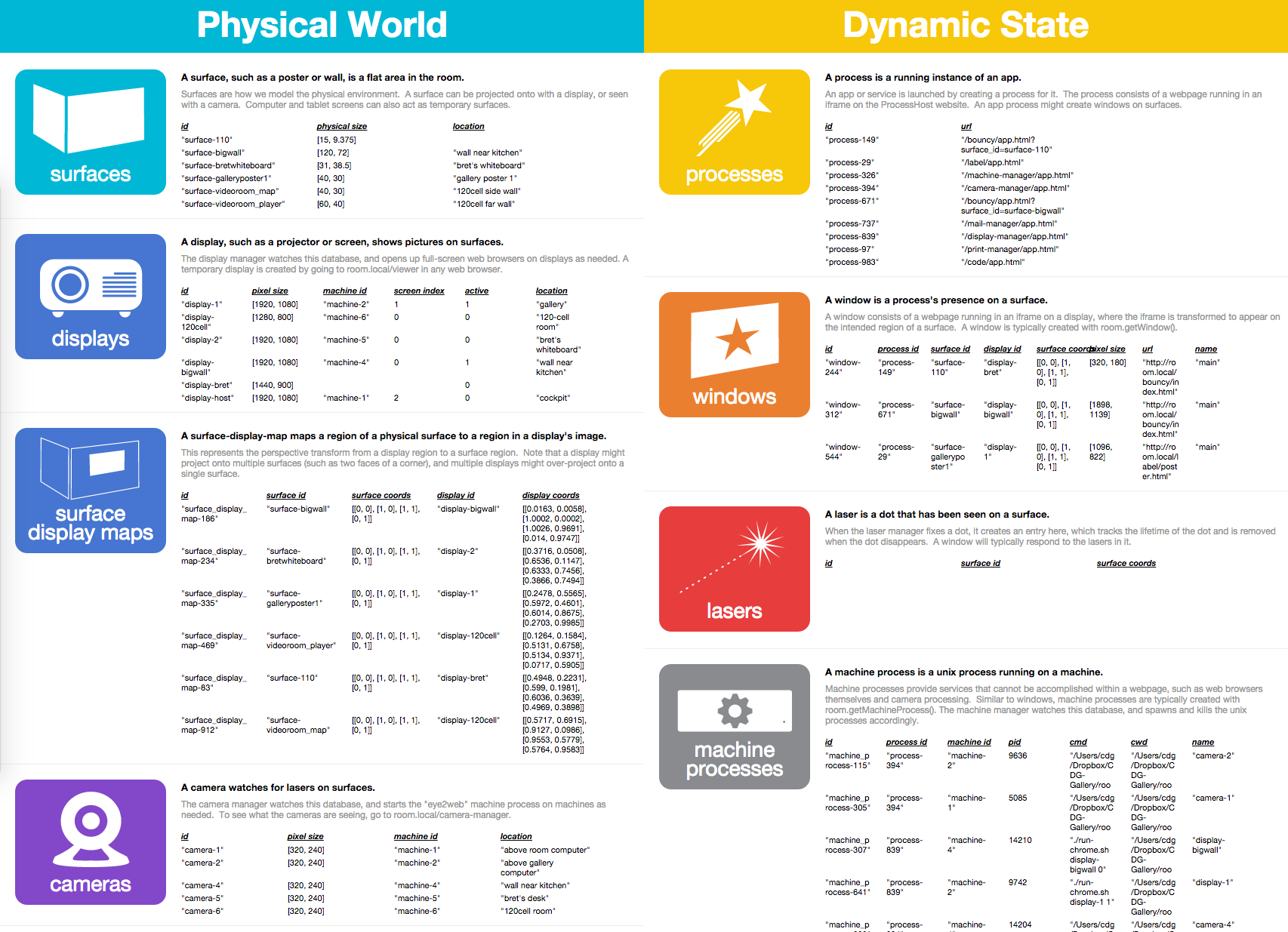
BigBoard shows "what" the state is. For a "database of meaning", we'd like to also show "why" the state is. "Why is this item here? What does it mean?"
We can approach a representation of "why" by trying to give context to the data with "when", "how", and "where".
When (timeline)
Things usually happen because other things happened. BigBoard currently only shows "now", but the server remembers everything that has ever happened, with a timestamp for each change.
At the very least, we'd like to see all of the state changes on a timeline. (In this mockup, the colors reflect the type of item -- red for laser, etc.)
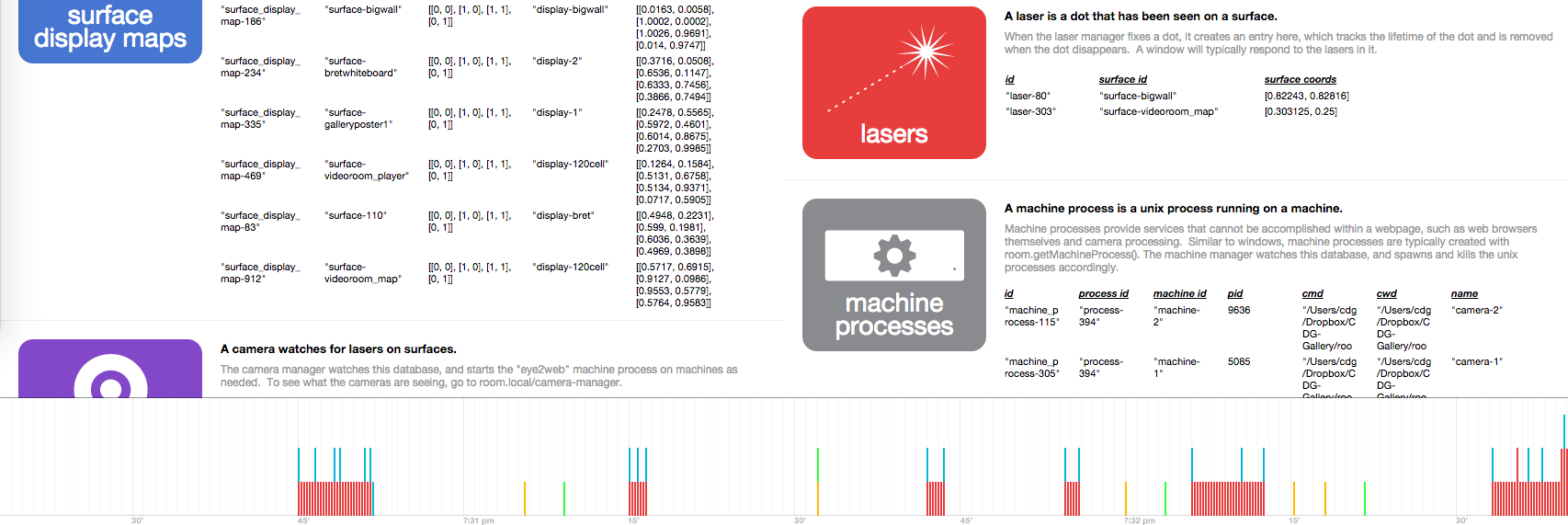
We could additionally see the changes for each type of item on its own little timeline.
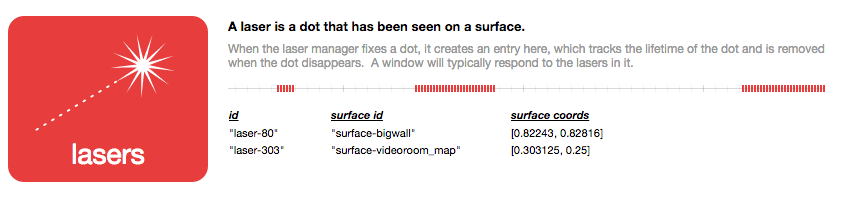
And perhaps a personal timeline for each item.
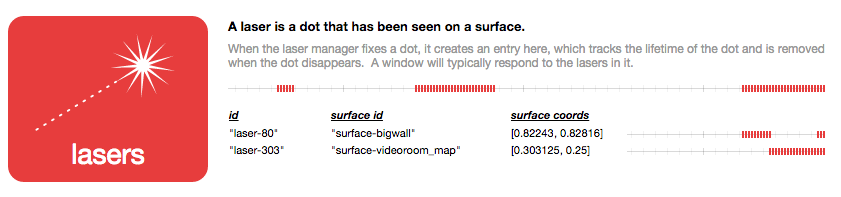
We'd like to be able to hover over any item and see its changes highlighted on the timeline.

As well as scrub over the timeline and see the entire database "rewound" to its state at that time, with the selected item highlighted.
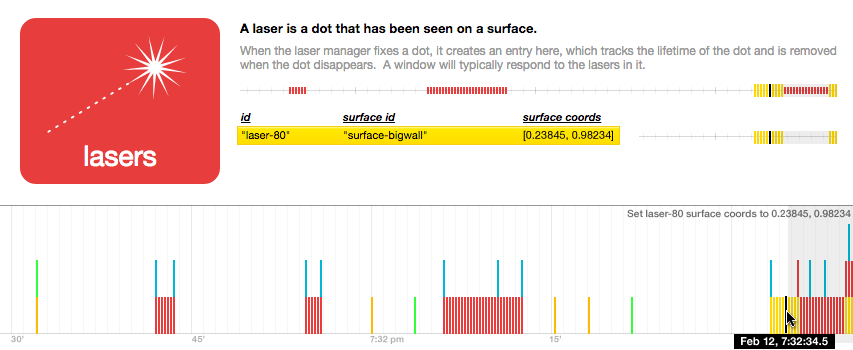
Could the timeline represent the future as well as the past? Could we simply scroll forward on the timeline and make changes to the database, which are "scheduled" to happen at the given time?
When (causality)
For Nile Viewer, I made a VM which recorded a "trace" for each loop iteration, recording which data was consumed and which data was produced. This allowed you to point to any data item and see where it "came from" and where it "went".

Our procedures aren't as structured as those in Nile, but we may be able to do something similar here. Most changes to the database are made in the event handler for some other change. RMO pointed out that when we save each item, we can attach the id of the item whose event we're handling. This should allow us to construct simple causality chains -- "selected_label" changed because a "touched_label" was added, because a "laser" changed.
These chains can be indicated on the timeline, perhaps by dimming out everything that isn't on the chain of the highlighted item.
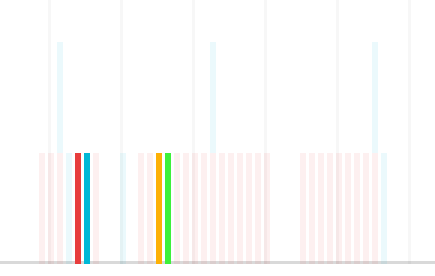
Or overlaid on the table view when hovering over an item.
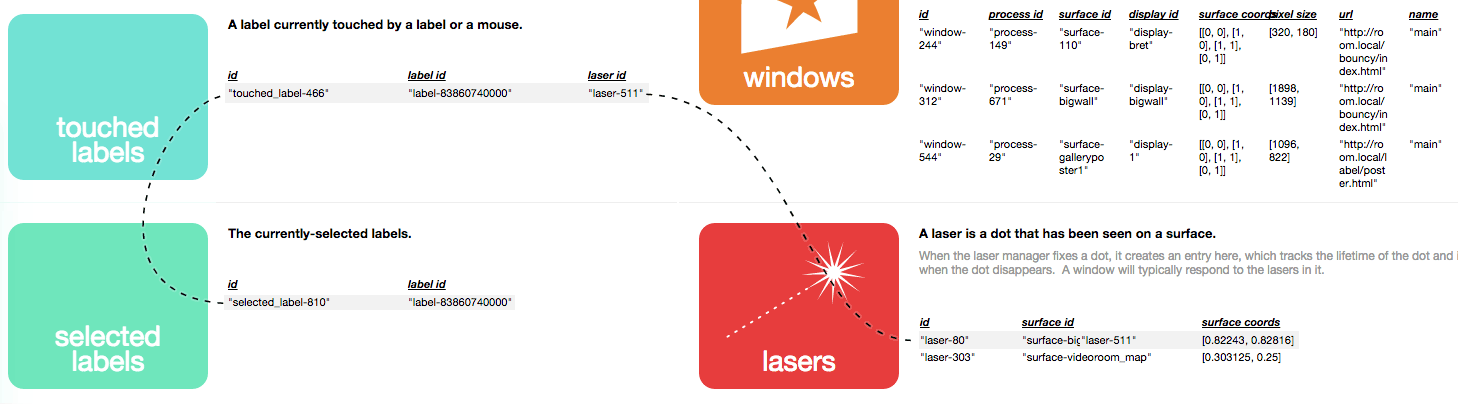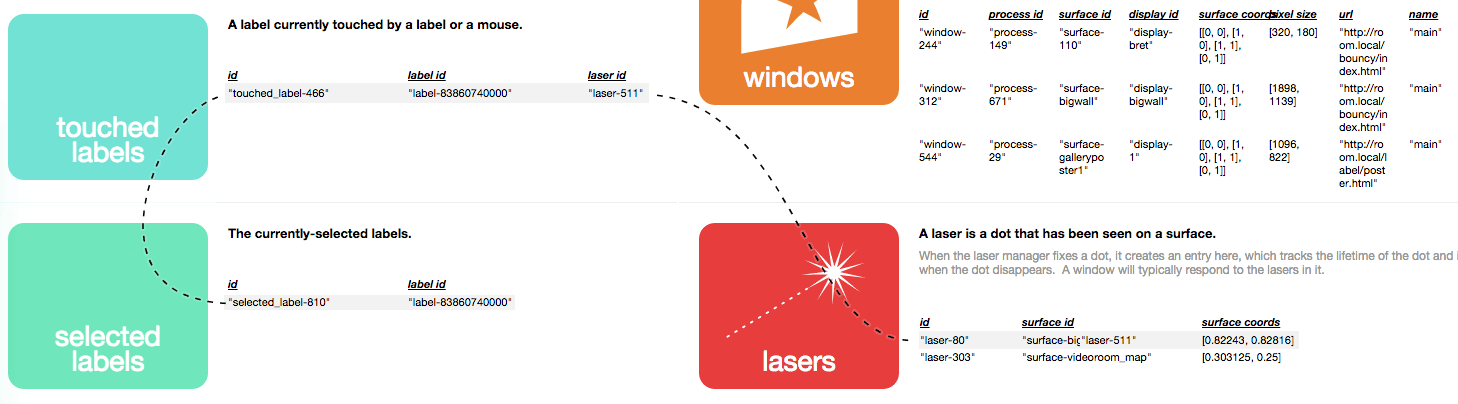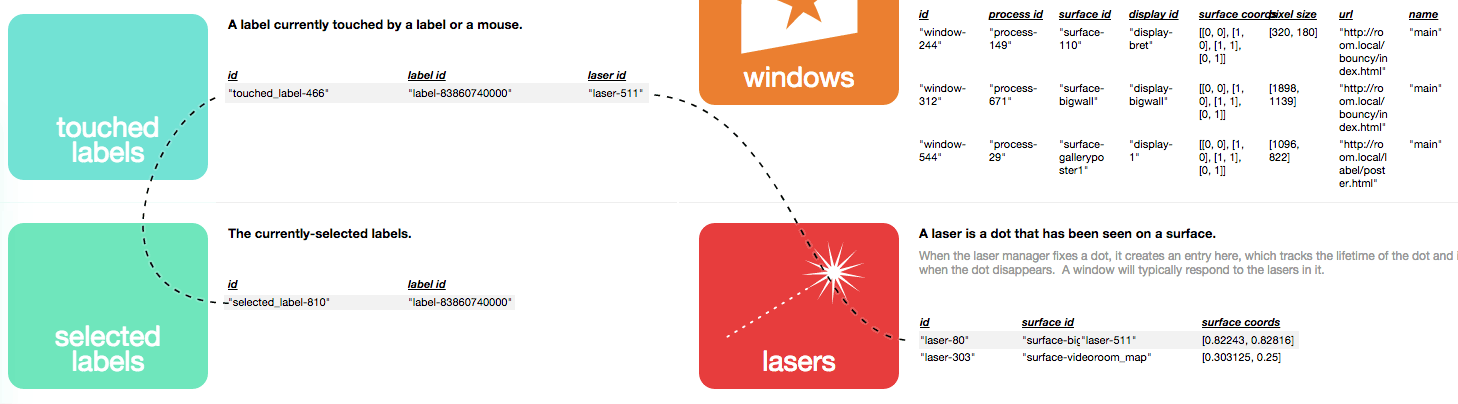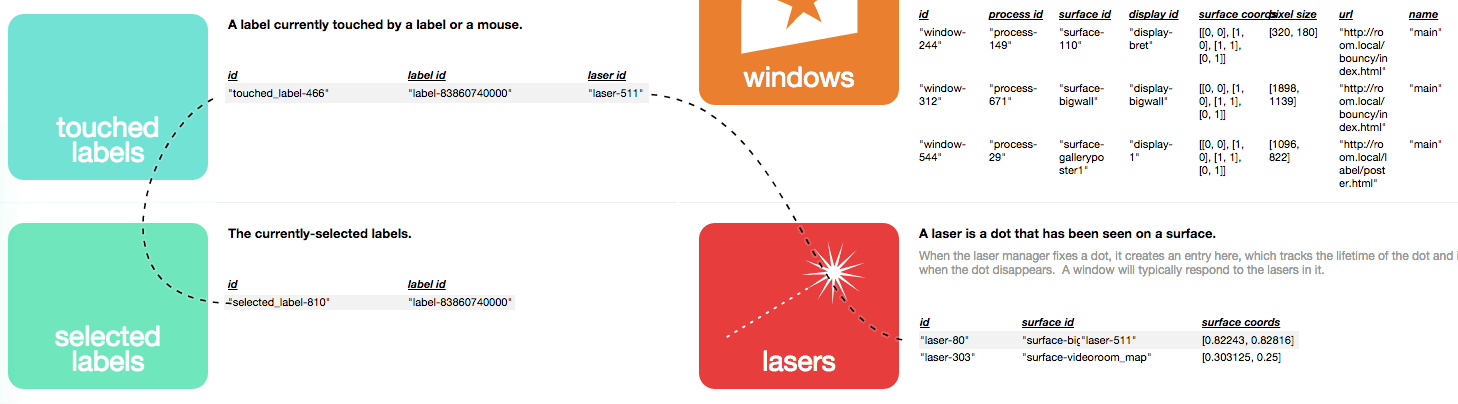
In an item's personal timeline, we can show not just "writes" to the item itself, but "reads" that influenced some other item.
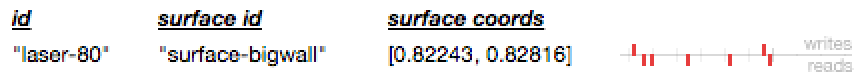
How (code view)
How did this data item get here? Some code put it there. We should, at least, be able to see the code responsible for the data.
Every time we save an item, we can attach a stack trace.
obj._tracebook = (new Error).stack;
When highlighting items in the database view, we can show the code that saved it.
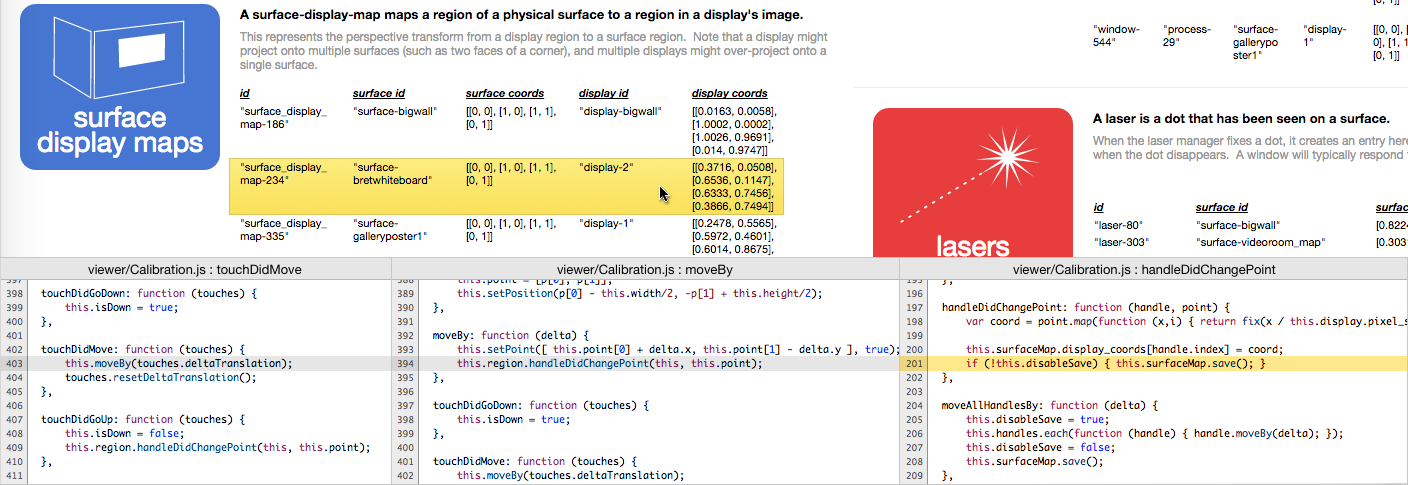
I suppose, once that's showing, we could go the other way, and highlight all items that were saved via this particular code path. (Though the non-highlighted ones are probably more interesting, since they must have been saved via some other path.)
It raises the question of whether an item should highlight if it was ever saved this way, or most recently saved this way. (Nile avoids this because it has no persistent objects that can be mutated.)
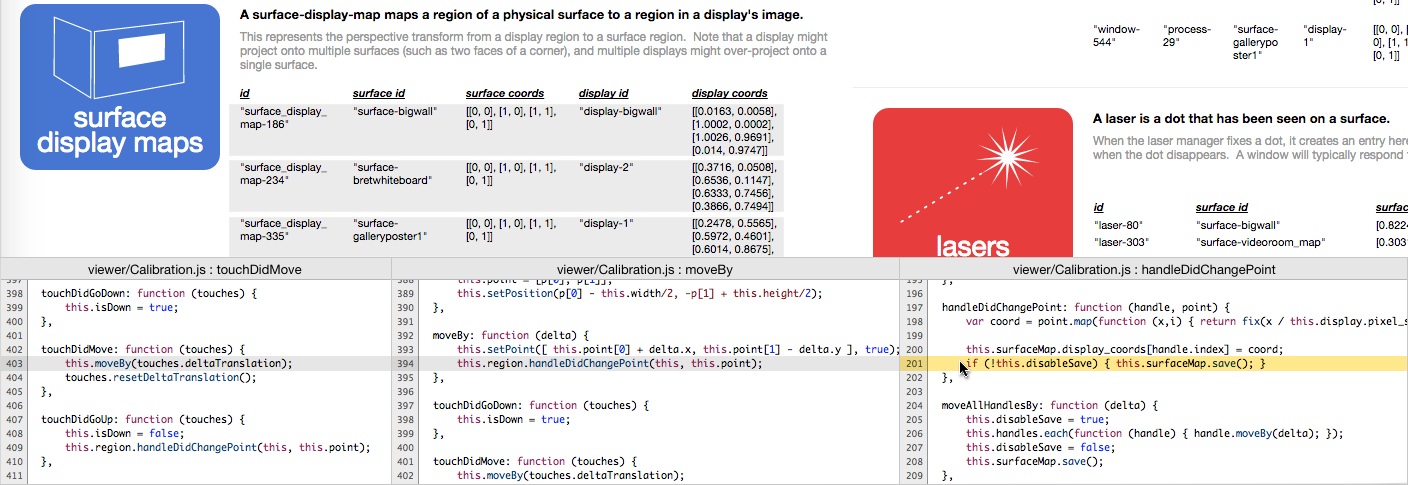
How (data transformations)
This code view, like the Smalltalk browser or any debugger, feels too "pinhole" for me. It would work if you have already internalized the entire codebase. But what we really want is a stable representation of the "shape of the whole [codebase]", where highlighting data would highlight the associated code within the whole.
I'm not sure how to do that, but it does make me want to come up with ways of specifying procedures that aren't buried in text files.
In a noun-oriented system like this one, most of the computation consists of transforming one data item to another. Displays transform into Chrome instances, camera images become lasers, become touched_labels, become selected_labels, etc.
I can imagine a way of specifying these transformations that feels more like directly editing the data. Basically like a spreadsheet, where you directly edit the fields of a mock output item, and define expressions and intermediate variables as needed. (This is not a good mockup.)
In addition to allowing us to define the transformation more clearly, such transformers allow us to show, after the fact, "how" any data item came to be, in a way that is more integrated with representation of the data item itself. In the database view, clicking on an item would show the actual transformation used to to produce the item, with all input and output fields filled out as above.
I think these transformers can obviate the need for many of our "processes", such as the "camera manager" and the "display manager". Banishing the daemons is probably good, as long as the transformers themselves (or perhaps "bundles" of related transformers) have a clear, stable, tangible presence.
Where
It seems that almost everything that is added to the database "by hand" (ie, not transformed from some other data by a process), has a physical location. (Machines, surfaces, displays, cameras, and even app processes (which run on some particular surface).) When we add to the database by hand, we are essentially trying to tell the system about something in the physical room, or something we want to be in the physical room.
This suggests a scale-model room, where the added-by-hand things are represented with physical tokens. You add a display to the system by literally placing a display token in the model.
This is the poster I was playing with before:
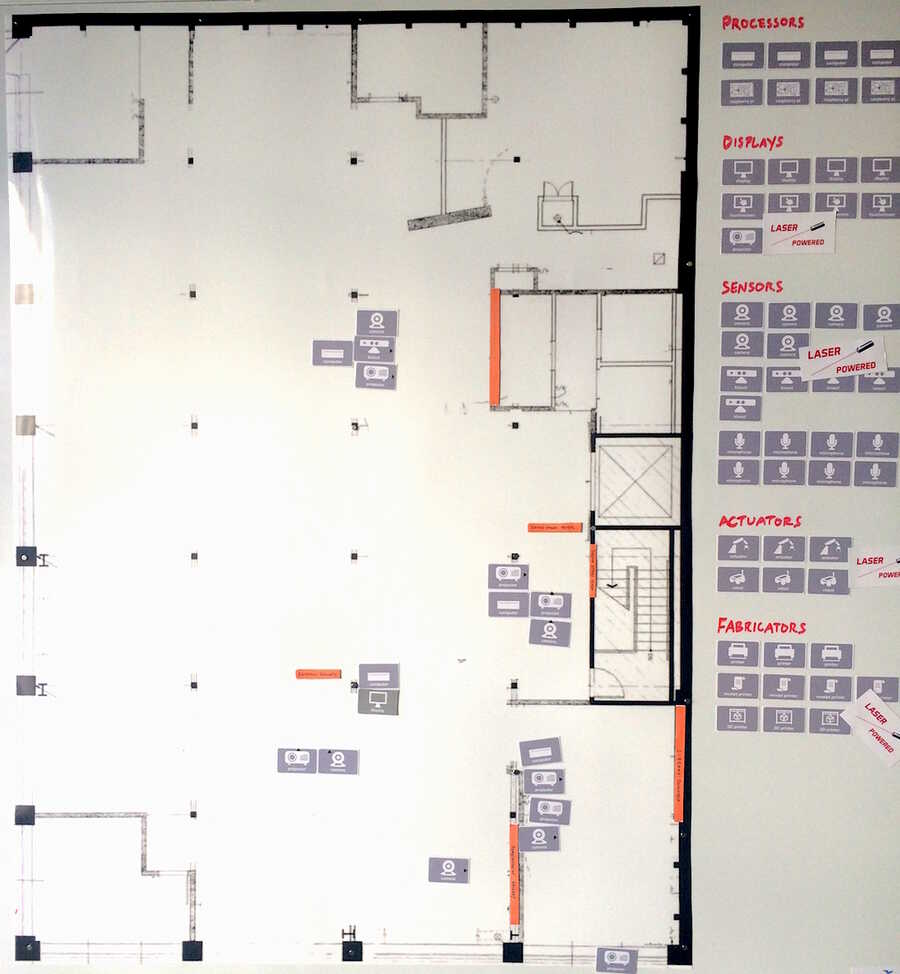
But I'm now imagining a horizontal "sand table" / "diorama" / "game board" model.


The vertical poster might be better for laser-pointing from far away, but the horizontal diorama maps better to the actual room (you don't have to mentally rotate from vertical to horizontal), and there's something interesting to me about manipulating the room via a scale model of the room. The tokens would be detected by an overhead camera, and we could do selective highlighting with an overhead projector.
The scale-model view and the "tables of data" database view would be linked -- anytime you are pointing to one, the other is highlighted, etc. Right now, there's a lot of confusion about "Which one is machine-3? Where is display-2?", and it's interesting to give meaning to that data using spatial location.
What (redux)
This gets back to the representation of the data items themselves. Right now, the primary representation of any "thing" is a table row:

which is conveniently generic, and certainly better than not being able to see the thing at all, but isn't really how a human being would naturally think about any particular thing.
One of the primary points of Nile Viewer was the power of seeing each form of data in a representation specific to that type of data (a set of points as dots in a plane, an array of numbers as a bar chart, etc), and the entire impetus for DDV was to create a method for specifying such data-specific representations by drawing them.
Much of the Nile data (or rather, Gezira data) is geometric, and has a natural visual representation. One of the most common criticisms of Everything I've Ever Done is that my visualizations work for geometric data, but wouldn't work for "real-world" data, where (ironically) "real-world" is taken to mean "too abstract to map to physical dimensions in the real world".
In the past, I've considered the problem (not necessarily the solution) of representing such abstract data as too obvious to be interesting (i.e., it's a straightforward design problem, and other designers will work on it). But this project provides some motivation for figuring out good representations for its nouns (ideally, multiple representations), and a good way of designing these representations (ideally, with Apparatus or similar).
Postscript
A "database of meaning" could be considered the inverse of the "Semantic Web". The Semantic Web is a machine-understandable representation of human affairs. A database of meaning is a human-understandable representation of machine affairs. AI vs IA, yet again.