Grilbert!
I think I’m starting to figure out the hierarchical possibilities, though this isn’t quite right yet:
For some reason I always forget that assembling big frames out of parts of little frames almost never a good idea.
I think I want zoomed-in levels to only show one of the containing frames, but to move along the hilbert track (in time & space). Likely I’ll have to implement this before that makes any sense.
This starts to show that the “land masses” can really start giving new possibilities, in terms of different sorts of zoom. Amazingly, this (sort of) works in all the desktop browsers.
Yr corresp,
r.m.o.
ps - dave, I’ve already had to serialize-and-destroy our “what’s good about griddle” whiteboard to even begin to understand the subtleties of hilbert indexing:
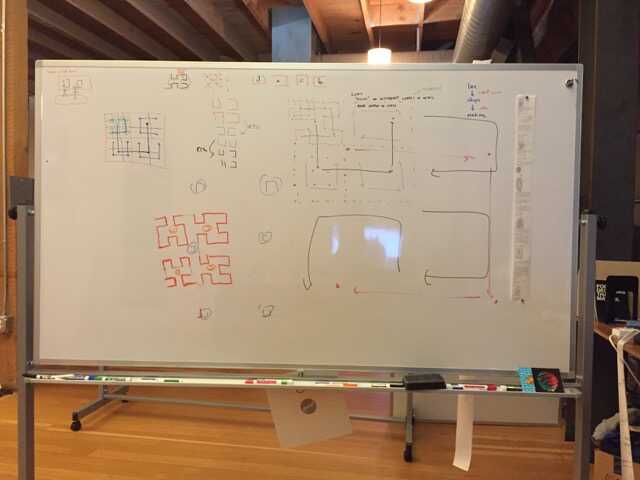
pps - chaim, i love your whitespace idea, but i don’t understand hilbert indexing well enough to know exactly how to implement it correctly, yet :-)
On Dec 5, 2014, at 9:12 PM, Bret Victor wrote:I think we need to explore something that's somewhere between Griddle and Hilbert (possibly Griddle at micro scale but Hilbert at macro scale), mostly just to use the name "Grilbert".
On Dec 5, 2014, at 3:22 PM, Dave Cerf wrote:I had similar thoughts, wanting a connect-the-dots line drawn from the center point of each frame to show their order in the grid of thumbnails. But then I thought, is this really what I want, or have we taken Hilbert too far in this case? For example, in a traditional linear thumbnail grid (Griddle, per RMO), we already know the order based on our reading skills: left to right, top to bottom. So we don’t need indicators at all—order is “intuitive” in the linear case.
RMO, maybe now is the time to photograph the whiteboard listing the benefits of the thumbnail grid, and then make a second list of benefits for the Hilbert Curve approach. When needed, a person can quickly switch between Hilbert and linear. For instance, in Hilbert, I like the recognizability of the “land masses” we see when zooming in and out, which is something totally absent from a linear grid.
Is one benefit of a dynamic medium the fact that representations can quickly transform from one to the other, smoothly enough to maintain orientation between the two? Maybe we can have multiple representations, of which Hilbert is one, and the new interaction isn’t so much learning about a new representation as it is learning to quickly and comfortably switch between representations as needed.
On Dec 5, 2014, at 12:58 PM, Chaim Gingold wrote:That’s really nice, and helps explain the curve.
But now I want even more cues. What if it charted out with light outlined empty rectangles, or a path, the near future of where the video will pour into? (Also, by the end, I want the source video to get out of the way again and situate itself below the thumbs.) After the video sits down the order is harder to see. What about something like this, and while I’m sure I’ve got the curve wrong hopefully the idea is clear, where adjacent neighborhoods slightly pull away from one another. As if it was all on paper and you cut along these neighborhood boundaries and pulled a little...
<PastedGraphic-3.tiff>On Dec 5, 2014, at 12:35 PM, Robert M Ochshorn wrote:
I was trying to keep it simple at first, but the pressures of the CDG prototyping environment escalated me towards the “spiral of death” design. Here’s another take:
<simple-hilbert-sm.mov>On Dec 5, 2014, at 11:14 AM, Chaim Gingold wrote:
lol
(i think?)On Dec 5, 2014, at 11:06 AM, Bret Victor wrote:
I hadn't realized there was a Poe's Law of prototyping.
On Dec 5, 2014, at 10:36 AM, Chaim Gingold wrote:On Dec 5, 2014, at 10:06 AM, Dave Cerf wrote:
It may or may not help, but I am impressed by the real-time Hilbertizing you pulled off. What I struggled to see here was the Hilbert pattern forming in the background—but even when the video is near full-size, is it moving in a Hilbert trajectory? Maybe if the images were more transparent when they were near full-size, I could see the formation of the small cells in the background.
...Or if the foreground video sat still, didn’t go off the page, or otherwise hide itself or what is happening underneath! Its motion distracts from the background activity. It mostly just needs to sit still and let us see the video unfolding while getting out of the way of the background activity.
I am reminded of our other discussion regarding “peeking” underneath something, both in regards to quoted text and the hand-flipping animation technique. Your video made me wish I could peek under the layers obscuring the final Hilbert grid underneath.
I was just thinking about rack focus as a method of changing interface “focus.” Perhaps this is just skeuomorphism and I should be fired along with Scott Forstall. Is the desire to bring familiar and comforting interfaces from the “real world” to screens and keyboards inherently regressive?
On Dec 4, 2014, at 7:07 PM, Robert M Ochshorn wrote:On Dec 3, 2014, at 9:57 PM, Dave Cerf wrote:
to better track with my eye what is going on
This may not help:
<hilbert-sm.mov>